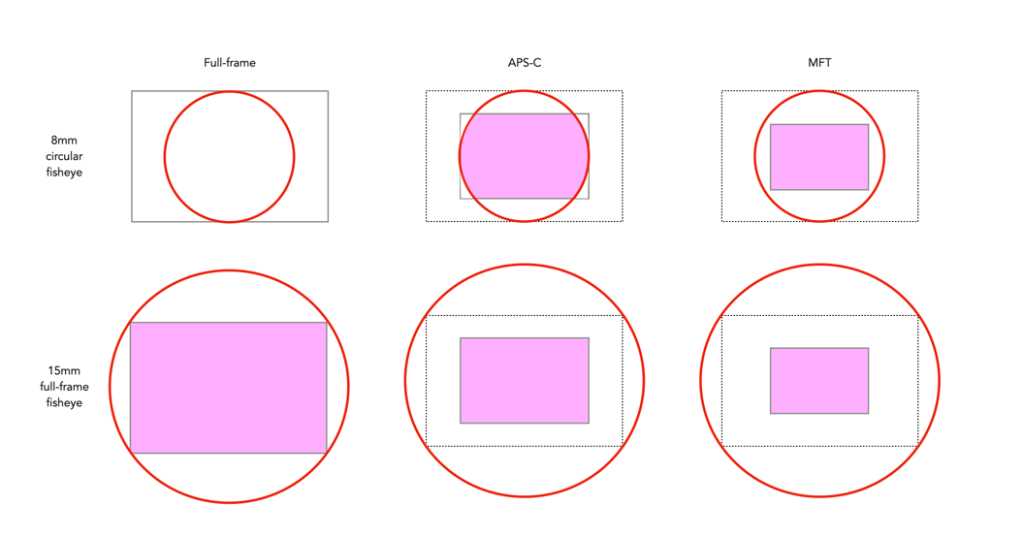
I love vintage lenses, and in the future, I will be posting much more on them. The question I want to look at here is the usefulness of vintage fish-eye lenses on crop sensors. Typically 35mm fisheye lenses are categorized into circular, and full-frame (or diagonal). A circular fisheye is typically in the range 8-10mm, with full-frame fisheye’s typically 15-17mm. The difference is shown in Figure 1.

The problem arises with the fact that fish-eye lenses are different. So different that the projection itself can be one of a number of differing types, for example equidistant, and equisolid. That aside, using a fisheye lens on a crop-sensor format produces much different results. This of course has to do with the crop factor. An 8mm circular fisheye on a camera with an APS-C sensor will have an AOV (Angle-of-View) equivalent to a 12mm lens. A 15mm full-frame fisheye will similarly have an AOV equivalent of a 22.5mm lens. A camera with a MFT sensor will produce an even smaller image. The effect of crop-sensors on both circular and full-frame fisheye lenses is shown in Figure 2.
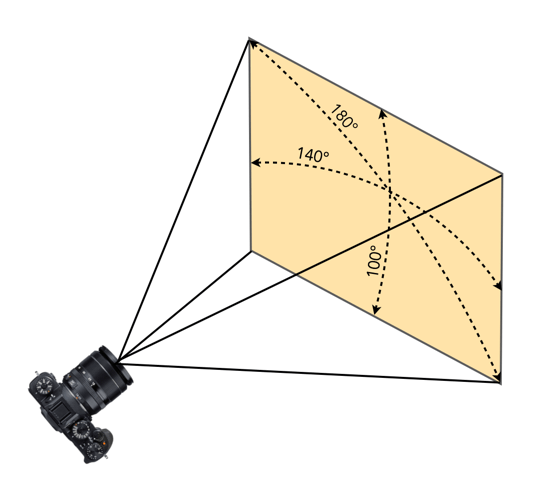
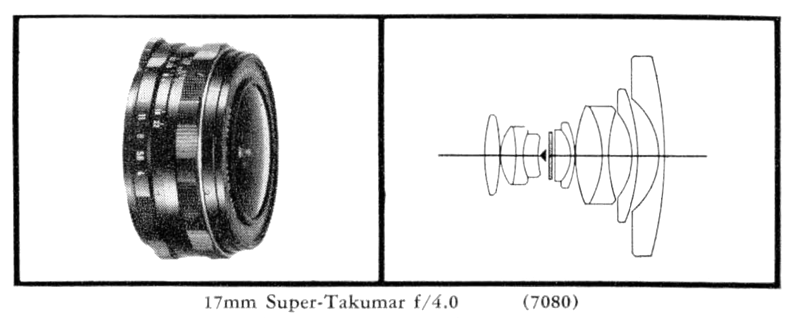
In particular, let’s look at the Asahi Super Takumar 17mm f/4 fish-eye lens. Produced from 1967-1971, in a couple of renditions, this lens has a 160° angle of view, in the diagonal, 130° in the horizontal. This is a popular vintage full-frame fisheye lens.
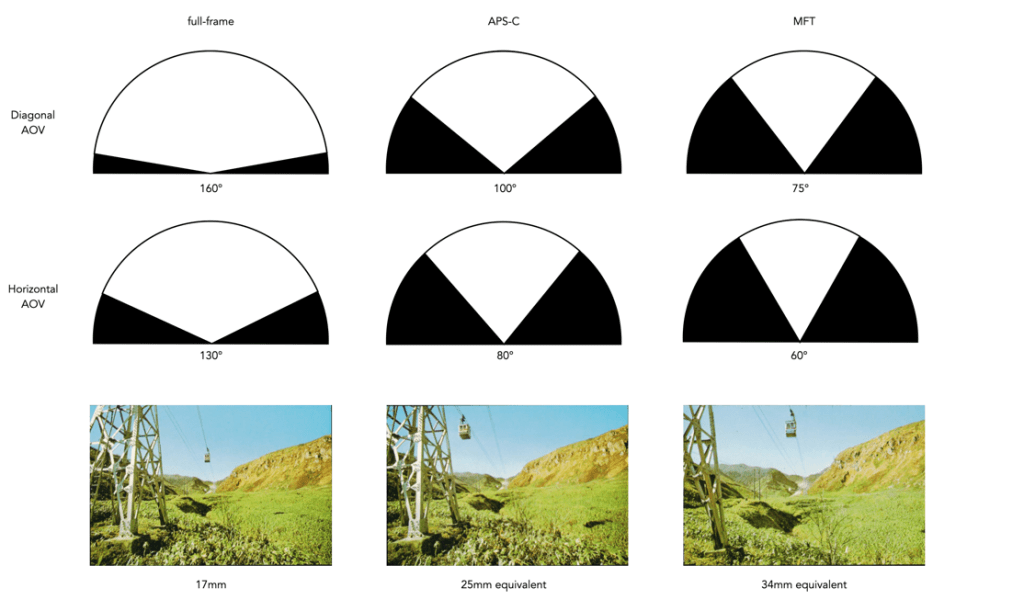
The effect of using this lens on a crop-sensor camera is shown in Figure 4. It effectively looses a lot of its fisheye-ness. In the case of an APS-C sensor, the 160° in the diagonal reduces to 100°, which is on the cusp of being an ultra-wide. When associated with a MFT sensor, the AOV reduces again to 75°, now a wide angle lens. Figure 4 also shows the horizontal AOV, which is easier to comprehend.
The bottom line is, that a full-frame camera is the best place to use a vintage fish-eye lens. Using one on a crop-sensor will limit its “fisheye-ness”. Is it then worthwhile to purchase a 17mm Takumar? Sure if you want to play with the lens, experiment with it’s cool built-in filters (good for B&W), or are looking for a wide-angle lens equivalent, any sort of fisheye effect will never be achieved. In many circumstances, if you want a more pronounced fisheye effect on a crop-sensor, it may be better to use a modern fisheye instead.
NB: Some Asahi Pentax catalogs suggest the 17mm has an AOV of 160°, while others suggest 180°.