Large format plate cameras offered a simple ground-glass screen, which offered many advantages, when speed of focusing and viewing aren’t really essential (and a tripod was being used). The viewfinder is large, and accurate and completely free of parallax. However there were also disadvantages: the image shown is inverted and laterally reversed, and the process of taking a photo was slow. When the Leica I rangefinder appeared in 1926, there was a new way of looking at things. But it too was not perfect, mainly because it suffered from parallax. Why? Part of the reason is that rangefinder cameras does not actually view the scene through the lens, but rather they use two “viewports” in order to get the split image to aid in focusing.

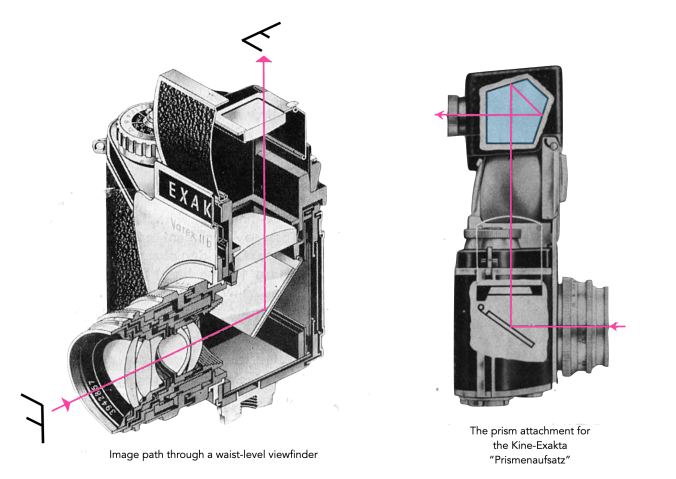
Now when the first 35mm SLR, the Exakta Kine, appeared a decade later, it sported a waist-level finder/viewfinder (WLF/WLV). Instead of being parallel to the lens axis, a WLV is perpendicular to the lens axis. These were standard on the Twin-Lens-Reflex cameras, such as the popular Rolleiflex, introduced in 1929 by Franke & Heidecke in Germany. The WLV naturally became standard with the appearance of the first small-format SLR, the VP Exakta a 127 roll film (4×6.5cm), in 1933. The camera viewed the scene through the lens, by means of a mirror which redirected the image 90°, vertically, the so-called “reflex-finder”. There was at that point, no prism to view the scene at eye-level. However there was also no issue with parallaxis. Indeed the VP Exakta was sold on the pretext that “Only a mirror reflected image as produced by the ‘Exakta’ lens is always reliable and absolutely identical with the final picture.”.

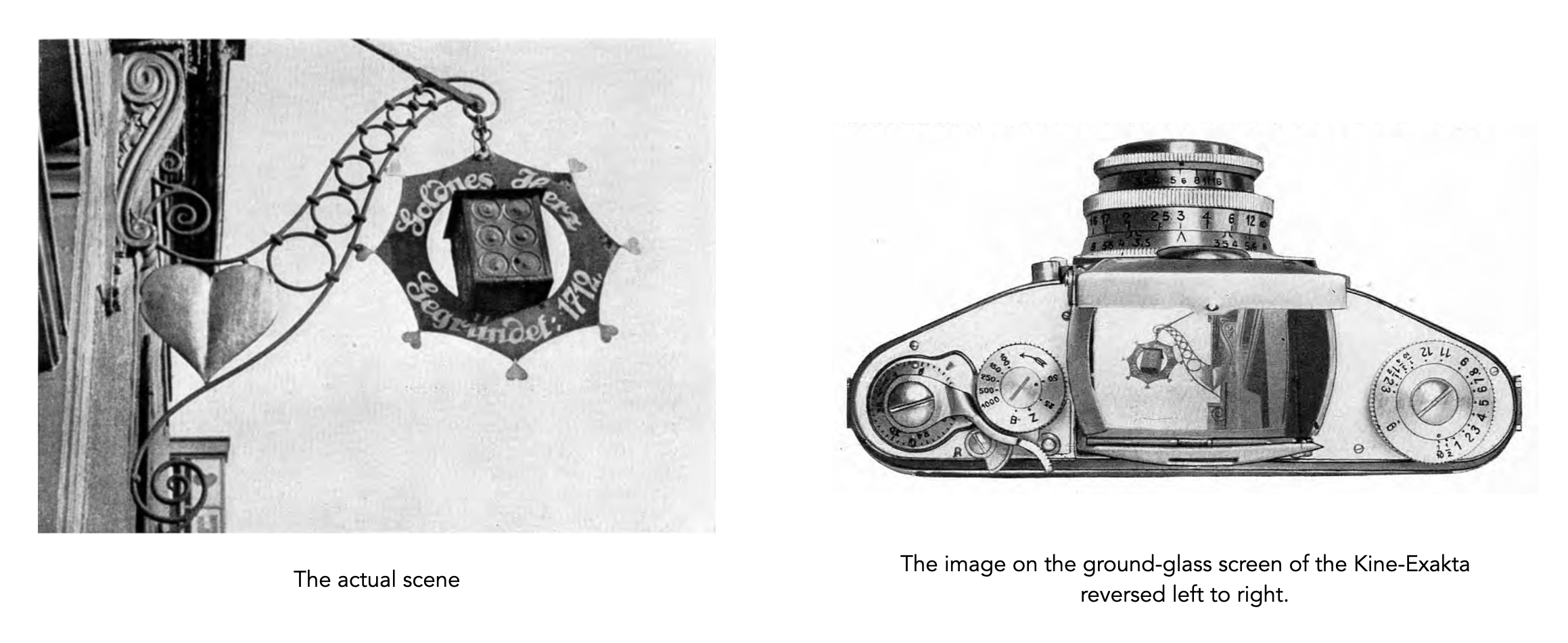
Many early SLRs came with a waist-level viewfinder, examples typically include cameras from Ihagee such as the Exakta. They had some benefits over previous systems. Firstly, the image is now the right way up, although still laterally reversed (so not ‘absolutely’ identical) (Fig.2). This allowed the camera to be used quite quickly − after focusing, the only real delay came from the time it takes to stop down the lens and swing the mirror out of the way. The WLF is often appreciated by street photographers, because it involves looking down to frame and focus, to bystanders it looks like a photographer is fooling about with the camera rather than preparing to shoot. It was also useful because the camera could be use upside down to allow shots to be taken over crowds.
However, for many, the positioning of the waist-level viewfinder was considered to be quite inconvenient, with the image on the screen still inverted when the camera is held to take portrait-framed pictures. This can be awkward in practice, and is likely why medium format cameras of the 1960s which typically used waist-level viewfinders, e.g. Bronica, Hasselblad, Praktisix adopted a 60mm (2¼-inch) square format. Focusing on a WLF was often harder as well. Cameras like the AsahiFlex II required focusing to be done by deciding when an image became clearest. To this end, may WLF often provided a magnifier attached to the rear finder hood. This is less of an issue with medium format cameras because it is easier to see the viewfinder just because of its larger size (the 24×36mm viewfinder is 24% of a 6×6 format camera).

The WLV was by no means ever meant to be the finale of viewfinders. Efforts were being made to provide an alternative ‘normal’ view through the lens. For Exakta cameras this was provided by means of a “Prismenaufsatz“, basically an auxiliary prism that was placed above the WLV. This appeared in 1949, and a new system of interchangeable viewfinders was designed by Willy Teubner, so that the existing viewfinder, including its housing could be removed and replaced with an insert with a prism [1]. This heralded the arrival of the Exakta Varex.
The waist-level viewfinder had incredible longevity. Some camera manufacturers included a WLV in their repertoire of interchangeable viewfinders right up until the early1960s, most notably German manufacturers such as Exakta (not surprisingly). Others like Kamera-Werkstätten moved to a fixed prism with the Praktica IV in 1959. Most Japanese companies abandoned the WLV quite quickly. Some, such as Asahi, went to a fixed pentaprism, with the introduction of the Pentax (1957), but in 1980 Pentax released the professional grade Pentax LX with interchangeable viewfinders, two of which were WLV’s. Miranda still supplied WLVs as an optional viewfinder until the 1970s, e.g. Miranda Sensorex II (1972).
Composing an image through a viewfinder certainly offers a different perspective on the scene being shot, and it does allow for a more discrete experience when undertaking street photography. However many of its advocates shoot TLR on medium format cameras, where the camera itself was better designed in order to shoot from the waist (both the shutter release and film advance are designed to be used at waist level). There has been recent interest in novelty optical waist-level finders for use on “any” camera. But the problem is that these sit on the top of a camera, and are by no means linked to the optical path of the lens. This is fine when the lens is auto-focus, or zone-focusing is used, but makes the entire process more tedious if the lens must be manually focused (because this requires framing and focusing through the lens viewfinder). The other problem is that they generally only work with 50mm or perhaps 35mm lenses, and are practically useless for others (because they don’t see through the lens).
Further reading:
- Teubner, W. (Ihagee Kamerawerk), DDR Nr.5410, “Viewfinder arrangement on SLR cameras with removable waist-level viewfinder” (Sub. 25 Apr. 1950)