Over a year ago I installed Spectre (for IOS). The thought of having a piece of software that could remove moving objects from photographs seemed like a real cool idea. It is essentially a long-exposure app which uses multiple images to create two forms of effects: (i) an image sans moving objects, and (ii) images with light (or movement) trails. It is touted as using AI and computational photography to produce these long exposures. The machine learning algorithms provide the scene recognition, exposure compensation, and “AI stabilization”, supposedly allowing for up to a 9-second handheld exposure without the need for a tripod.
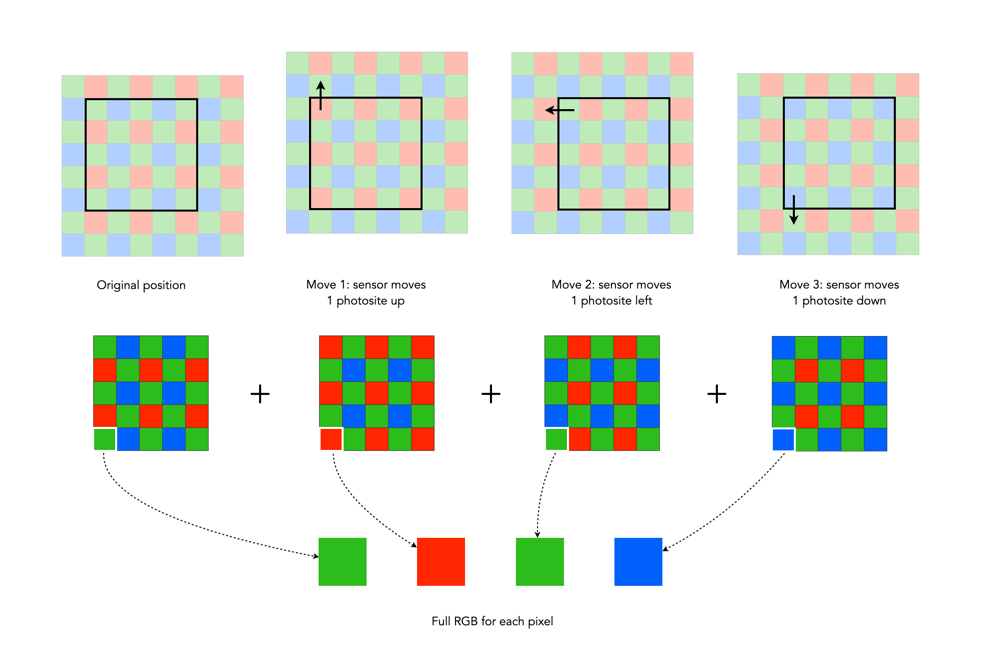
It seems as though the effects are provided by means of a computational photography technique known as “image stacking“. Image stacking just involves taking multiple images, and post-processing the series to produce a single image. For removing objects, the images are averaged. The static features will be retained in the image, the moving features will be removed through the image averaging process – which is why a stable image is important. For the light trails it works similar to a long exposure on a digital camera, where moving objects in the image become blurred, which is usually achieved by superimposing the moving features from each frame on the starting frame.
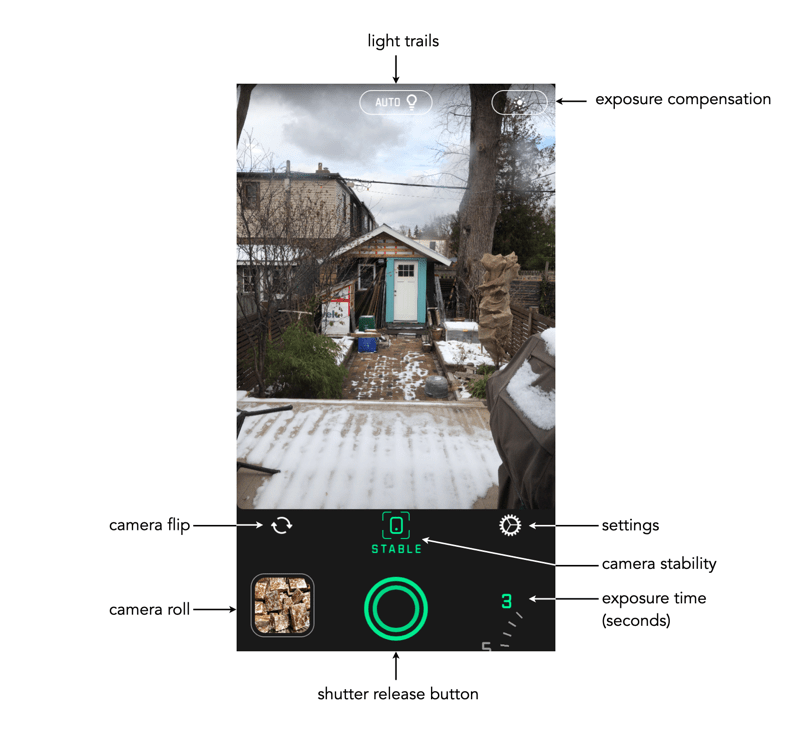
The app is very easy to use. Below the viewing window are a series of basic controls: camera flip; camera stabilization, and settings. The stabilization control, when activated, provides a small visual feature that determines when the iPhone is STABLE. As Spectre can perform a maximum of 9 seconds worth of processing, stabilization is an important attribute. The length of exposure is controlled by a dial in the lower-right corner of the app – you can choose between 3, 5, and 9 seconds. The Settings really only allows the “images” to be saved as Live Photos. The button at the top-middle turns light trails to ON, OFF, or AUTO. The button in the top-right allows for exposure compensation, which can be adjusted using a slider. The viewing window can also be tapped to set the focus point for the shot.

Using this app allows one of two types of processing. As mentioned, one of these modes is the creation of trails – during the day these are motion trails, and at night these are light trails. Motion trails are added by turning “light trails” to the “ON” position (Fig.4). The second mode, with “light trails” to the “OFF” position, basically removes moving objects from the scene (Fig.3)


It is a very simple app, for which I do congratulate the app designers. Too many photo-type app designers try and cram 1001 features into an app, often overwhelming the user.
Here are some caveats/suggestions:
- Sometimes motion trails occur because the moving object is too long to fundamentally change the content of the image stack. A good example is a slow moving train – the train never leaves the scene, during a 9-second exposure, and hence gets averaged into a motion trail. This is an example of a long-exposure image, as aptly shown in Figure 2. It’s still cool from as aesthetics point-of-view.
- Objects must move in and out of frame during the exposure time. So it’s not great for trying to remove people from tourist spots, because there may be too many of them, and they may not move quick enough.
- Long exposures tend to suffer from camera shake. Although Spectre offers an indication of stability, it is best to rest the camera on at least one stable surface, otherwise there is a risk of subtle motion artifacts being introduced.
- Objects moving too slowly might be blurred, and still leave some residual movement in a scene where moving objects are to be removed.
Does this app work? The answer is both yes and no. During the day the ideal situation for his app is a crowded scene, but the objects/people have to be moving at a good rate. Getting rid of parked cars, and slow people is not going to happen. Views from above are obviously ideal, or scenes where the objects to be removed are moving. For example, doing light trails of moving cars at night produces cool images, but only if they are taken from a vantage point – photos taken at the same level of the cars only results in producing a band of bright light.
It would actually be cool if they could extend this app to allow for times above nine seconds, specifically for removing people from crowded scenes. Or perhaps allowing the user to specify a frame count and delay. For example, 30 frames with a 3 second delay between each frame. It’s a fun app to play around with, and well worth the $2.99 (although how long it will be maintained is another question, the last update was 11 months ago).