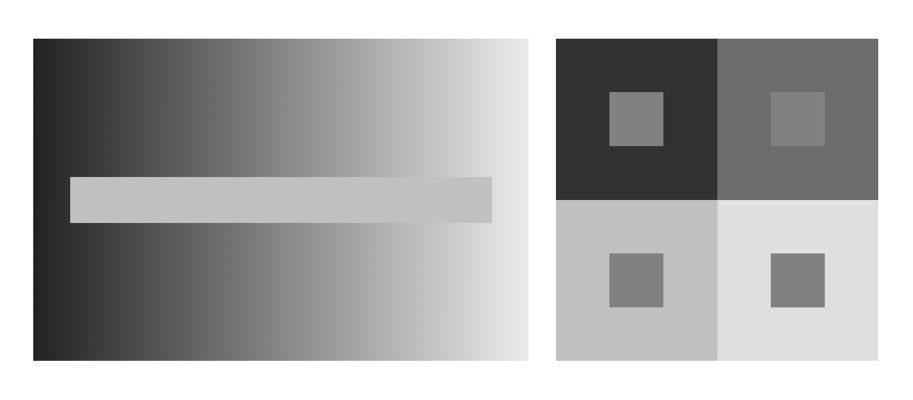That’s pretty obvious right? But the eye sees things a little differently. The process of looking at a photograph is by no means trivial.
The thing is that the human eye does not stand still. Try focusing your eye on an object for a minute or two. After just a few seconds your eyes will begin to tire, and you long to move them onto something new. By the time you reach a minute, if you have even made it that long, you will struggle to continue staring at the object – your eyes are well past being bored. How many times during the day do you suppose you look at anything for more than a few seconds? (the TV doesn’t count because the picture changes) The answer is likely not many. The same can be said of people that look at the photographs we take. After an initial view, their eyes become restless, longing to move on.
In reality, most people will spend less than a minute looking at a photograph, especially if they have seen the subject/object of the picture before. The only person who really spends a great deal of time looking at a photograph is the person who took it. So with such a short viewing time-span it is important for an image to contain an interesting subject, and provide enough distraction to spend longer considering its message. To do this you have to somehow control movement of the viewers eyes through the picture.
The simplest “scene” can be construed in different ways with respect to eye control.
The first step involves grabbing a viewers attention. Therefore there should be something in the image that is outstanding or unusual. In the second phase, the viewer should be made to understand the story of the image. This is all about the flow of the image, with the viewer being lead through the composition. The third step involves maintaining the viewers gaze by getting them interested in the details of the image. Examples are shown in the figure above.
As I have mentioned before, the standard Angle-of-View (AOV) of the human visual system (HVS) is about 60° (horizontally) – the central field of vision, so to speak. So why do companies still tout 50mm lenses as being “close to the angle of view of the human eye”? It’s honestly hard to know. Zeiss still describes its Touit 32mm f/1.8 as offering “…the same angle of view as the human eye.“, with a horizontal AOV of 40°. The dominant “standard” lens for full-frame has been the 50mm since the introduction of the Leica by Barnack in 1925. That’s nearly a century of using a lens that doesn’t really duplicate the AOV of human vision, mostly because it simplifies human vision far too much. It doesn’t even match the 43.3mm diagonal of the 36×24mm frame – which is normally the golden standard of a “normal” lens.
A 50mm lens has a horizontal AOV of 39.6°, which only comes close to representing the region of the HVS that deals with symbol recognition, which is a somewhat narrow scope. In fact, most people aren’t really concerned about whether they are using a lens that “approximates human vision”. One of the most talked about lenses in the Fuji-X environment is the 23mm lens, which is close to a 35mm in full-frame land. In all likelihood, there has probably been a gradual move away from 50mm towards the wider focal lengths. For example the iPhone 14 has two rear facing cameras: a 13mm ultra-wide, and a 26mm wide (equiv). No 50mm at all. With a wider AOV it is possible to crop from within the frame.
What a 28mm iPhone camera lens sees (orange) versus the smaller AOV of a 50mm lens (blue)
Some would probably advocate for the actual diagonal of a full-frame, i.e. 43mm. This would give an AOV of 45°, midway between 30 and 60 degrees. But is this optimal? I think it comes down to personal preference. I personally think that a 60° is likely a better approximation for a lens. So which lens better represents the 60°? For full-frame it is likely around 31mm, or around 20-21mm for APS-C. So we end up in the spectrum of wide lenses, and that’s not necessarily a bad thing. Humans visualize the world around them in terms of a wide lens – yes not all of it is in complete focus, but then the HVS works in much different ways to a camera lens.
A standard colour image is 8-bit (or 24-bit) containing 2563 = 16,777,216 colours. That seems like a lot right? But can that many colours even be distinguished by the human visual system? The quick answer is no, or rather we don’t exactly know for certain. Research into the number of actual discernible colours is actually a bit of a rabbit’s hole.
A 1998 paper [1] suggests that the number of discernible colours may be around 2.28 million – the authors determined this by calculating the number of colours within the boundary of the MacAdam Limits in CIELAB Uniform Colour Space [2] (for those who are interested). However even the authors suggested this 2.28M may be somewhat of an overestimation. An larger figure of 10 million colours (from 1975) is often cited [3], but there is no information on the origin of this figure. A similar figure of 2.5 million colours was cited in a 2012 article [4]. A more recent article [5] gives a conservative estimate of 40 million distinguishable object color stimuli. Is it even possible to realistically prove such large numbers? Somewhat unlikely, because it may be impossible to quantify – ever. Indications based on existing colour spaces may be as good as it gets, and frankly even 1-2 million colours is a lot.
Of course the actual number of colours someone sees is also dependent on the number and distribution of cones in the eye. For example, dichromat’s only have two types of cones which are able to perceive colour. This colour deficiency manifests differently depending on which cone is missing. The majority of the population are trichromats, i.e. they have three types of cones. Lastly there are the very rare individuals, the tetrachromats who have four different cones. Supposedly tetrachromats can see 100 million colours, but it is thought the condition only exists in women, and in reality, nobody really knows how many are potentially tetrachromatic [6] (and the only definitive way of finding out if you have tetrachromacy is via a genetic test).
The reality is that few if any real pictures contain 16 million colours. Here are some examples (all images contain 9 million pixels). Note the images are shown in association with the hue distribution from the HSB colour-space. The first example is a picture of a wall of graffiti art in Toronto. Now this is an atypical image because it contains a lot of varied colours, most images do not. This image has only 740,314 distinct colours – that’s only 4.4% of the potential colours available.
The next example is a more natural picture, a picture of two building (Nova Scotia). This picture is quite representative of images such as landscapes, that are skewed towards quite a narrow band of colours. It only contains 217,751 distinct colours, or 1.3% of the 16.77 million colours.
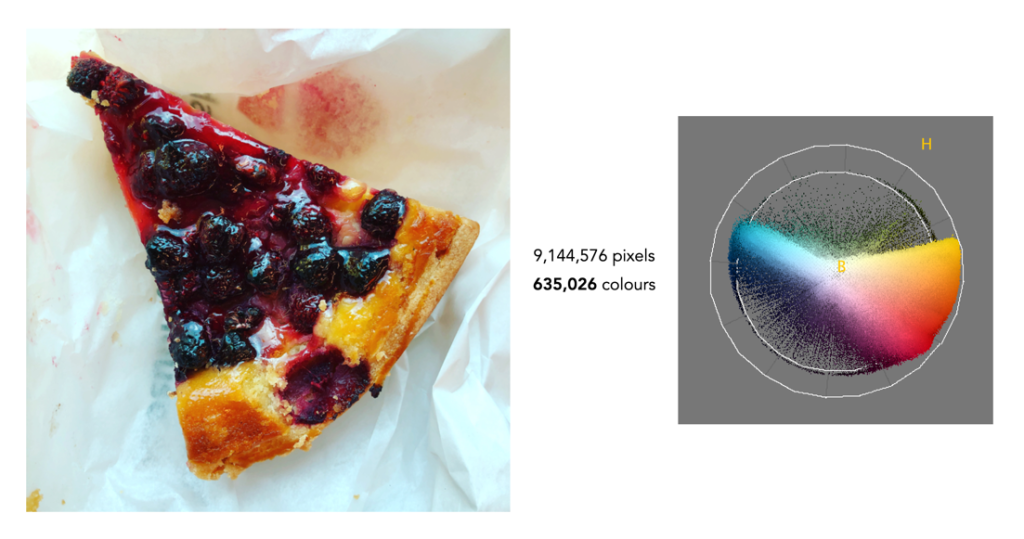
Finally we have foody-type image that doesn’t seem to have a lot of differing colours, but in reality it does. There are 635,026 (3.8%) colours in the image. What these examples show is that most images contain fewer than one million different colours. So while there is the potential for an image to contain 16,777,216 colours, in all likely they won’t.
What about 10-bit colour? We’re taking about 10243 or 1,073,741,824 colours – which is really kind of ridiculous.
Further reading:
Pointer, M.R., Attridge, G.G., “The number of discernible colours”, Color Research and Application, 23(1), pp.52-54 (1998)
MacAdam, D.L., “Maximum visual efficiency of colored materials”, Journal of the Optical Society of America, 25, pp.361-367 (1935)
Judd, D.B., Wyszecki, G., Color in Business, Science and Industry, Wiley, p.388 (1975)
Flinkman, M., Laamanen, H., Vahimaa, P., Hauta-Kasari, M., “Number of colors generated by smooth nonfluorescent reflectance spectra”, J Opt Soc Am A Opt Image Sci Vis., 29(12), pp.2566-2575 (2012)
Kuehni, R.G., “How Many Object Colors Can We Distinguish?”, Color Research and Application, 41(5), pp.439-444 (2016)
Jordan, G., Mollon, J., “Tetrachromacy: the mysterious case of extra-ordinary color vision”, Current Opinion in Behavioral Sciences, 30, pp.130-134 (2019)
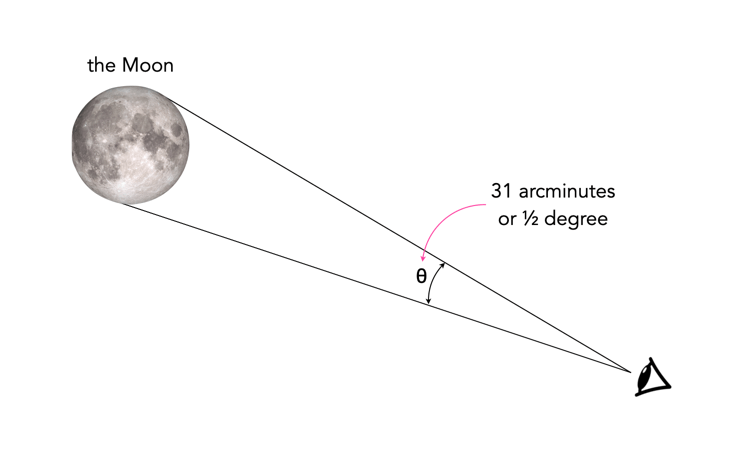
The number of megapixels required to print something, or view a television is ultimately determined by the human eye’s visual acuity, and the distance the object is viewed from. For someone with average vision (i.e. 20/20), their acuity would be defined as one arcminute, or 1/60th of a degree. For comparison, a full moon in the sky appears about 31 arcminutes (1/2 a degree) across (Figure 1).
Fig.1: Looking at the moon
Now generally, some descriptions skip from talking about arcminutes to describing how the distance between an observer and an object can calculated given the resolution of the object. For example, the distance (d, in inches) at which the eye reaches its resolution limit is often calculated using:
d = 3438 / h
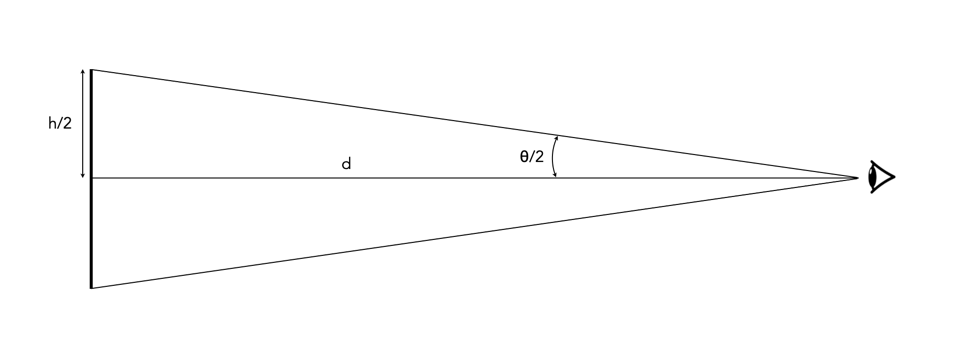
Where h, is the resolution, and can be ppi for screens, and dpi for prints. So if h=300, then d=11.46 inches. Now to calculate the optimal viewing distance involves a magic number – 3438. Where does this number come from? Few descriptions actually give any insights, but we can can start with some basic trigonometry. Consider the diagram in Figure 2, where h is the pixel pitch, d is the viewing distance, and θ is the angle of viewing.
Fig.2: Viewing an object
Now we can use the basic equation for calculating an angle, Theta (θ), given the length of the opposite and adjacent sides:
tan(θ) = opposite/adjacent
In order to apply this formula to the diagram in Figure 2, only θ/2 and h/2 are used.
tan(θ/2) = (h/2)/d
So now, we can solve for h.
d tan(θ/2) = h/2
2d⋅tan(θ/2) = h
Now if we use visual acuity as 1 arcminute, this is equivalent to 0.000290888 radians. Therefore:
h = 2d⋅tan(0.000290888/2)
= 2d⋅0.000145444
So for d=24”, h= 0.00698 inches, or converted to mm (by multiplying by 25.4), h=0.177mm. To convert this into PPI/DPI, we simply take the inverse, so 1/0.00698 = 143 ppi/dpi. How do we turn this equation into one with the value 3438 in it? Well, given that the resolution can be calculated by taking the inverse, we can modify the previous equation:
So for a poster viewed at d=36″, the value of h=95dpi (which is the minimum). The viewing distance can be calculated by rearranging the equation above to:
d = 3438 / h
As an example, consider the Apple Watch Series 8, whose screen has a resolution of 326ppi. Performing the calculation gives d=3438/326 = 10.55”. So the watch should be held 10.55” from one’s face. For a poster printed at 300dpi, d=11.46”, and for a poster printed at 180dpi, d=19.1”. This is independent of the size of the poster, just printing resolution, and represents the minimum resolution at a particular distance – only if you move closer do you need a higher resolution. This is why billboards can be printed at a low resolution, even 1dpi, because when viewed from a distance it doesn’t really matter how low the resolution is.
Note that there are many different variables at play when it comes to acuity. These calculations provide the simplest case scenario. For eyes outside the normal range, visual acuity is different, which will change the calculations (i.e. radians expressed in θ). The differing values for the arcminutes are: 0.75 (20/15), 1.5 (20/30), 2.0 (20/40), etc. There are also factors such as lighting, how eye prescriptions modify acuity, etc. to take into account. Finally, it should be added that these acuity calculations only take into account what is directly in front of our eyes, i.e. the narrow, sharp, vision provided by the foveola in the eye – all other parts of a scene, will have slightly less acuity moving out from this central point.
Fig.3: At 1-2° the foveola provides the greatest amount of acuity.
p.s. The same system can be used to calculate ideal monitor and TV sizes. For a 24″ viewing distance, the pixel pitch is h= 0.177mm. For a 4K (3840×2160) monitor, this would mean 3840*0.177=680mm, and 2160*0.177=382mm which after calculating the diagonal results in a 30.7″ monitor.
p.p.s. If using cm, the formula becomes: d = 8595 / h
There is a third difference between cameras and the human visual system (HVS). While some camera lenses may share a similar perspective of the world with the HVS with respect to the angle-of view, where they differ is what is actually in the area of focus. Using any lens on a camera means that a picture will have an area where the scene is in-focus, with the remainder being out-of-focus. This in-focus region generally occurs in a plane, and is associated with the depth-of-field. On the other hand, the in-focus region of the picture our mind presents us does not have a plane of focus.
While binocular vision allows approximately 120° of (horizontal) vision, it is only highly focused in the very centre, with the remaining picture being increasingly out-of-focus depending on how far a point is away from the central focused region. This may be challenging to visualize, but if you look at an object, only the central point is in focus, the remainder of the picture is out-of-focus. That does not mean it is necessarily blurred, because the brain is still able to discern shape and colour, just not fine details. Blurring it usually a function of distance from the object being focused on, i.e. the point-of-focus. If you look at a close object, distant objects will be out-of-focus, and vice versa.
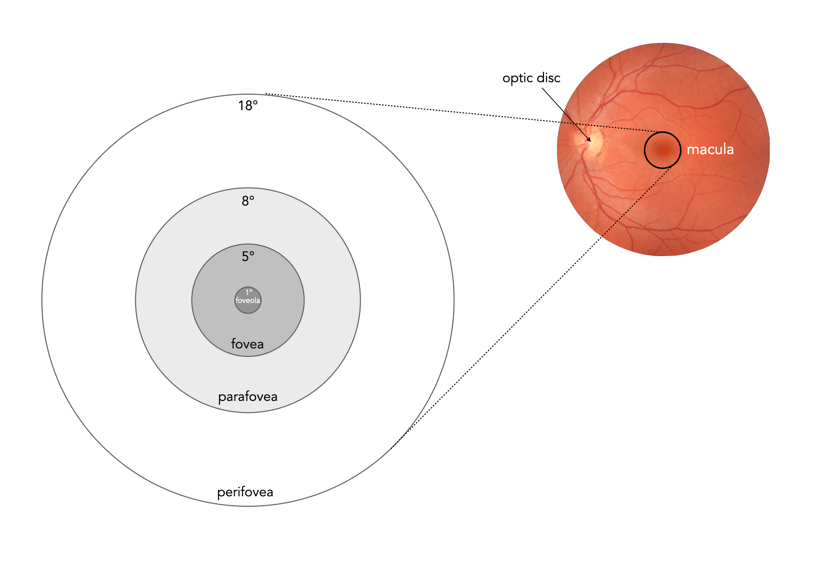
Fig.1: Parts of the macula
Focused vision is related to the different parts of the macula, an oval-shaped pigmented area in the centre of the retina which is responsible for interpreting vision, colour, fine details, and symbols (see Figure 1). It is composed almost entirely of cones, into a series of zones:
perifovea (5.5mm∅, 18°) : Details that appear in up to 9-10° of visual angle.
parafovea (3mm∅, 8°) : Details that appear in peripheral vision, not as sharp as the fovea.
fovea (1.5mm∅, 5°) : Or Fovea centralis, comprised entirely of cones, and responsible for high-acuity, and colour vision.
foveola (0.35mm∅, 1°) : A central pit within the fovea, which contains densely packed cones. Within the foveola is a small depression known as the umbo (0.15mm∅), which is the microscopic centre of the foveola.
Fig.2: Angle-of-view of the whole macula region, versus the foveola.The foveola provides the greatest region of acuity, i.e. fine details.
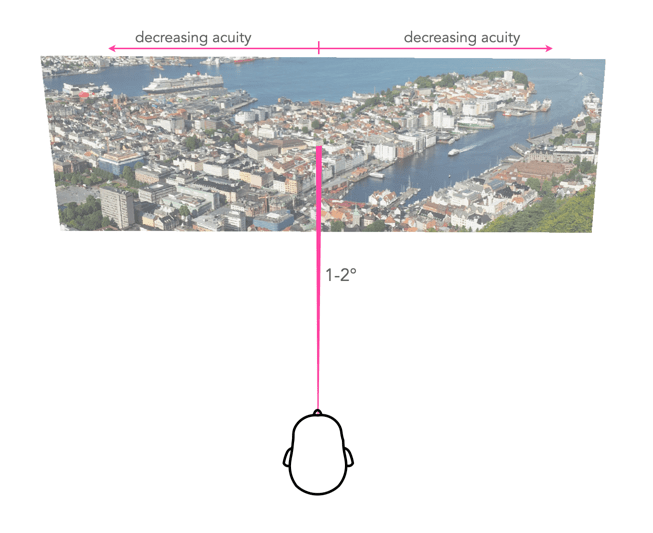
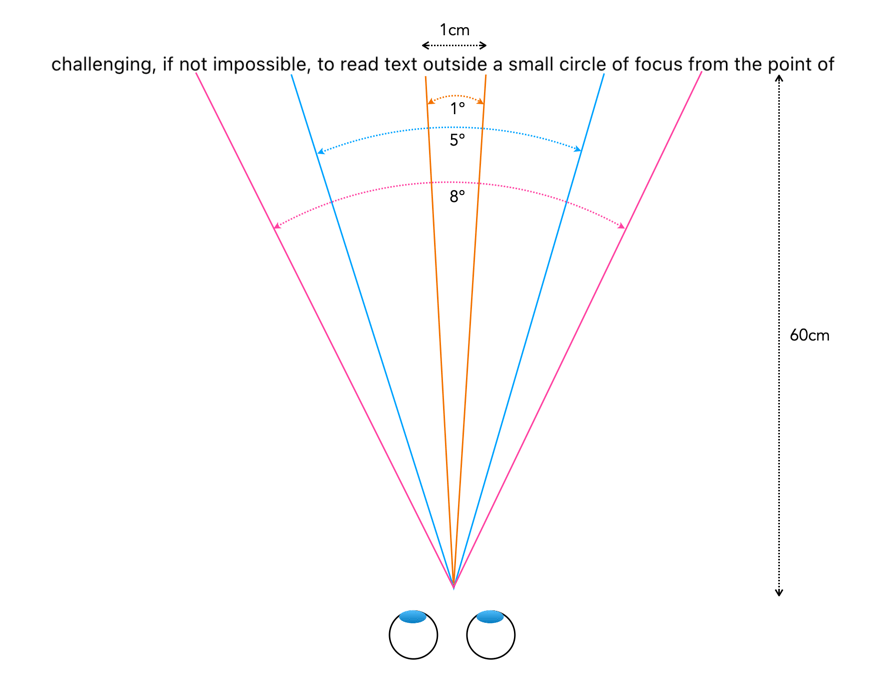
When we fixate on an object, we bring an image of that object onto the fovea. The foveola provides the greatest amount of visual acuity, in the area 1-2° outwards from the point of fixation. As the distance from fixation increases, visual acuity decreases quite rapidly. To illustrate this effect, try reading the preceding text in this paragraph while fixating on the period at the end of the sentence. It is likely challenging, if not impossible, to read text outside a small circle of focus from the point of fixation. A seven letter word, like “outside”, is about 1cm wide, which when read on a screen 60cm from your eye represents about an angle of 1°. The 5° of the fovea region allows for a “preview” of the words either side, and parafovea region, 8° of peripheral words (i.e. their shape). This is illustrated in Figure 3.
Fig.3: Reading text from 60cm
To illustrate how this differential focus affects how humans view a scene, consider the image shown in Figure 4. The point of focus is a building in the background roughly 85m from where the person is standing. This image has been modified by adding radial blur from a central point-of-focus to simulate in-focus versus out-of-focus regions as seen by the eye (the blur has been exaggerated). The sharpest region is the point of fixation in the centre – from this focus on a particular object, anything either side of that object will be unsharp, and the further away from that point, the more unsharp is becomes. The
Fig.4: A simulation of focused versus out-of-focus regions in the HVS (the point of fixation is roughly 85m from the eyes)
It is hard to effectively illustrate exactly how the HVS perceives a scene as there is no way of taking a snapshot and analyzing it. However we do know that focus is a function of distance from the point-of-focus. Other parts of an image as essentially de-emphasized, there is still information there, and the way our minds process it, it provides a complete vision, but there is a central point of focus.
Further reading:
Ruch, T.C., “Chapter 21: Binocular Vision, and Central Visual Pathways”, in Neurophysiology (Ruch, T.C. et al. (eds)) p.441-464 (1965)
There are a number of fundamental differences between a “normal” 50mm lens and the human visual system (HVS). Firstly, a camera extracts a rectangular image from the circular view of the lens. The HVS on the other hand is not circular, nor rectangular – if anything it has somewhat of an oval shape. This can be seen in the diagram of binocular field of vision shown in Figure 1 (from [1]). The central shaded region is the field of vision seen by both eyes, i.e. binocular (stereoscopic) vision, the white areas on both sides are the monocular crescents, seen by only by each eye, and the blackened area is not seen.
Fig.1: One of the original diagrams illustrating both the shape of vision, and the extent of binocular vision [1].
Figure 1 illustrates a second difference, the fact that normal human vision is largely binocular, i.e. uses both eyes to produce an image, whereas most cameras are monocular. Figure 2 illustrates binocular vision more clearly, comparing it to the total visual field.
Fig.2: Shape and angle-of-view, total versus binocular vision (horizontal).
The total visual field of the HVS is 190-200° horizontally, which is composed of 120° of binocular vision, and two fields of 35-40° seen by one one eye. Vertically, the visual field of view is about 130° (and the binocular field is roughly the same), comprised of 50° above the horizontal line-of-sight, and 70-80° below it. An example to illustrate binocular vision (horizontal) is shown in Figure 3.
Fig.3: A binocular (horizontal – 120°) view of Bergen, Norway
It is actually quite challenging to provide an exact example of what a human sees – largely because trying to take the same picture would require a lens such as a fish-eye which would introduce distortions, something the HVS is capable of filtering out.
Further reading:
Ruch, T.C., “Chapter 21: Binocular Vision, and Central Visual Pathways”, in Neurophysiology (Ruch, T.C. et al. (eds)) p.441-464 (1965)
Most colour images are stored using a colour model, and RGB is the most commonly used one. Digital cameras typically offer a specific RGB colourspace such as sRGB. It is commonly used because it is based on how humans perceive colours, and has a good amount of theory underpinning it. For instance, a camera sensor detects the wavelength of light reflected from an object and differentiates it into the primary colours red, green, and blue.
An RGB image is represented by M×N colour pixels (M = width, N = height). When viewed on a screen, each pixel is displayed as a specific colour. However, deconstructed, an RGB image is actually composed of three layers. These layers, or component images are all M×N pixels in size, and represent the values associated with Red, Green and Blue. An example of an RGB image decoupled into its R-G-B component images is shown in Figure 1. None of the component images contain any colour, and are actually grayscale. An RGB image may then be viewed as a stack of three grayscale images. Corresponding pixels in all three R, G, B images help form the colour that is seen when the image is visualized.
Fig.1: A “deconstructed” RGB image
The component images typically have pixels with values in the range 0 to 2B-1, where B is the number of bits of the image. If B=8, the values in each component image would range from 0..255. The number of bits used to represent the pixel values of the component images determines the bit depth of the RGB image. For example if a component image is 8-bit, then the corresponding RGB image would be a 24-bit RGB image (generally the standard). The number of possible colours in an RGB image is then (2B)3, so for B=8, there would be 16,777,216 possible colours.
Coupled together, each RGB pixel is described using a triplet of values, each of which is in the range 0 to 255. It is this triplet value that is interpreted by the output system to produce a colour which is perceived by the human visual system. An example of an RGB pixel’s triplet value, and the associated R-G-B component values is shown in Figure 2. The RGB value visualized as a lime-green colour is composed of the RGB triplet (193, 201, 64), i.e. Red=193, Green=201 and Blue=64.
Fig.2: Component values of an RGB pixel
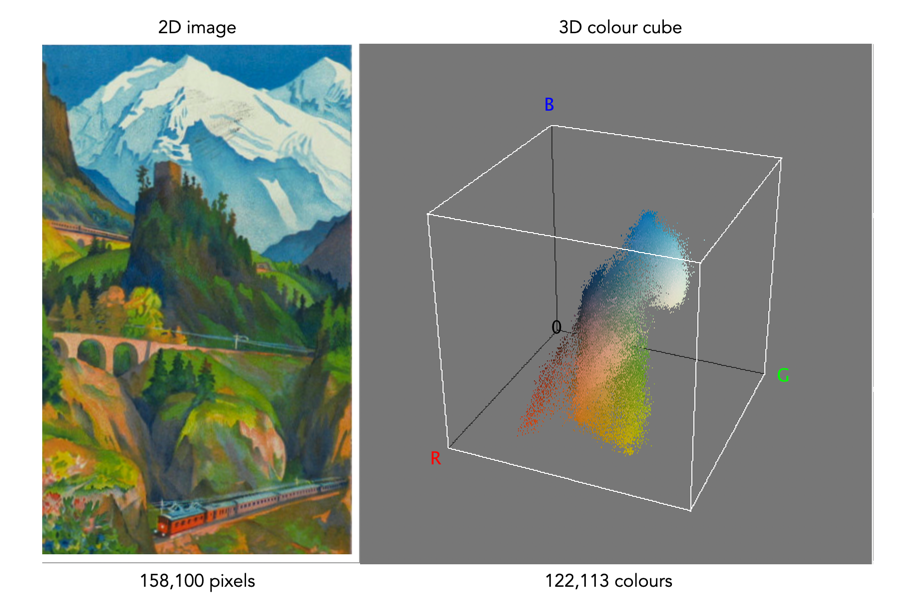
One way of visualizing the R,G,B, components of an image is by means of a 3D colour cube. An example is shown in Figure 3. The RGB image shown has 310×510, or 158,100 pixels. Next to it is a colour cube with the three axes, R, G, and B, each with a range of values 0-255, producing a cube with 16,777,216 elements. Each of the images 122,113 unique colours is represented as a point in the cube (representing only 0.7% of available colours).
Fig 2 Example of colours in an RGB 3D cube
The caveat of the RGB colour model is that it is not a perceptual one, i.e. chrominance and luminance are not separated from one another, they are coupled together. Note that there are some colour models/space that are decoupled, i.e. they separate luminance information from chrominance information. A good example is HSV (Hue, Saturation, Value).
How often do we stop and think about how colour blind people perceive the world around us? For many people there is a reduced ability to perceive colours in the same way that the average person perceives them. Colour blindness, which is also known as colour vision deficiency affects some 8% of males, and 5% of females. Colour blindness means that a person has difficulty seeing red, green, or blue, or certain hues of these colours. In extremely rare cases, a person have an inability to see any colour at all. And one term does not fit all, as there are many differing forms of colour deficiency.
The most common form is red/green colour deficiency, split into two groups:
Deuteranomaly – 3 cones with a reduced sensitivity to green wavelengths. People with deuteranomaly may commonly confuse reds with greens, bright greens with yellows, pale pinks with light grey, and light blues with lilac.
Protanomaly – The opposite of deuteranomaly, a reduced sensitivity to red wavelengths. People with protanomaly may confuse black with shades of red, some blues with reds or purples, dark brown with dark green, and green with orange.
Then there is also blue/yellow colour deficiency. Tritanomaly is a rare color vision deficiency affecting the sensitivity of the blue cones. People with tritanomaly most commonly confuse blues with greens and yellows with purple or violet.
Standardvision
Deuteranomaly
Protanomaly
Tritanomaly
People with deuteranopia, protanopia, or tritanopia are the dichromatic forms where the associated cones (green, red, or blue) are missing completely. Lastly there is monochromacy, achromatopsia, or total colour blindness are conditions of having mostly defective or non-existent cones, causing a complete lack of ability to distinguish colours.
Standard vision
Deuteranopia
Protanopia
Tritanopia
How does this affect photography? Obviously photographs will be the same, but photographers who have a colour deficiency will perceive a scene differently. For those interested, there are some fine articles on how photographers deal with colourblindness.
Check here for an exceptional article on how photographer Cameron Bushong approaches colour deficiency.
Photographer David Wilder offers some insights into working on location and some tips for editing.
Some examples of what the world looks like when your colour-blind.
Below is a rendition of the standard colour spectrum as it relates to differing types of colour deficiency.
Simulated colour deficiencies applied to the colour spectrum.
In reality people who are colourblind may be better at discerning some things. A 2005 article [1] suggests people with deuteranomaly may actually have an expanded colour space in certain circumstances, making it possible for them to for example discern subtle shades of khaki.
Note: The colour deficiencies shown above were simulated using ImageJ’s (Fiji) “Simulate Color Blindness” function. An good online simulator is the Coblis, Color Blindness Simulator.
Humans don’t interpret gray tones very well – the human visual system perceiving approximately 32 shades of gray. So an 8-bit image with 256 tones already contains too much information for humans to interpret. That’s why you don’t really see any more clarity in a 10-bit image with 1024 shades of gray than a 5-bit image with 32 shades of gray. But why do we only see approximately 32 shades of gray?
It is the responsibility of the rod receptors to deal with black and white. The rods are far less precise than the cones which deal with colour, but are more sensitive to low levels of light that are typically associated with being able to see in a dimly lit room, or at night. There are supposedly over 100 million rods in the retina, but this doesn’t help distinguish any more than 30-32 shades of gray. This may stem from evolutionary needs – in the natural world there are very few things that are actually gray – stones, some trunks of trees, weathered wood, so there was very little need to distinguish between more than a few shades of gray. From an evolutionary perspective, humans needed night vision because they lived half their lives in darkness. This advantage remained crucial, apart perhaps form the past 150 years or so.
The rods work so well that dark adapted humans can detect just a handful of photons hitting the retina. It is likely this is the reason there are so many rods in the retina – so that in exceedingly low levels of light as many as possible of the scarce photons are captured by rods. Figure 1 illustrates two grayscale optical illusions, which rely on our eyes insensitivity to shades of gray. In the image on the left, the horizontal strip of gray is actually the same shade throughout, although our eyes deceive us into thinking that it is light on the left and dark on the right. in the image on the right, the inner boxes are all the same shade of gray, even though they appear to be different.
Fig.1: Optical illusions
To illustrate this further, consider the series of images in the figure below. The first image is the original colour image. The middle image shows that image converted to grayscale with 256 shades of gray. The image on the right shows the colour image converted to 4-bit grayscale, i.e. 16 shades of gray. Is there any perceptual difference between Fig.2b and 2c? Hardly.
Fig.2a: Original colour
Fig.2b: 8-bit grayscale
Fig.2c: 4-bit grayscale
You will see articles that suggest humans can see anywhere from 500-750 shades of gray. They are usually articles related to radiology, where radiologists interpret images like x-rays. The machines that take these medical images are capable of producing 10-bit or 12-bit images which are interpreted on systems capable of improving contrast. There may of course be people that can see more shades of gray, just like there are people with a condition called aphakia that possess ultraviolet vision (aphakia is a lack of a lens which normally blocks UV light, so they are able to perceive wavelengths up to 300nm). There are also tetrachromats who posses a fourth cone cell, allowing them to see up to 100 million colours.
How humans perceive colour is interesting, because the technology of how digital cameras capture light is adapted from the human visual system. When light enters our eye it is focused by the cornea and lens into the “sensor” portion of the eye – the retina. The retina is composed of a number of different layers. One of these layers contains two types of photosensitive cells (photoreceptors), rods and cones, which interpret the light, and convert it into a neural signal. The neural signals are collected and further processed by other layers in the retina before being sent to the brain via the optic nerve. It is in the brain that some form of colour association is made. For example, an lemon is perceived as yellow, and any deviation from this makes us question what we are looking at (like maybe a pink lemon?).
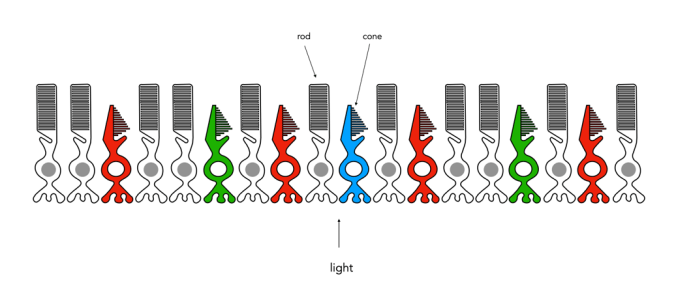
Fig.1: An example of the structure and arrangement of rods and cones
The rods, which are long and thin, interpret light (white) and darkness (black). Rods work only at night, as only a few photons of light are needed to activate a rod. Rods don’t help with colour perception, which is why at night we see everything in shades of gray. The human eye is suppose to have over 100 million rods.
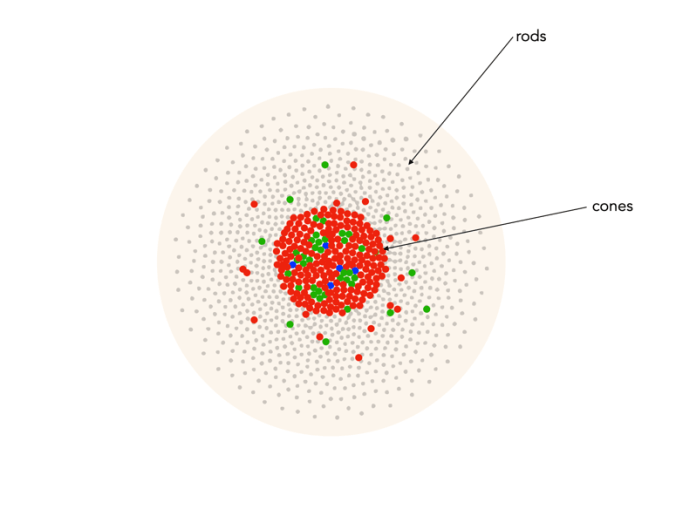
Cones have tapered shape, and are used to process the the three wavelengths which our brains interpret as colour. There are three types of cones – short-wavelength (S), medium-wavelength (M), and long-wavelength (L). Each cone absorbs light over a broad range of wavelengths: L ∼ 570nm, M ∼ 545nm, and S ∼ 440nm. The cones are usually called R, G, and B for L, M, and S respectively. Of course these cones have nothing to do with their colours, just wavelengths that our brain interprets as colours. There are roughly 6-7 million cones in the human eye, divided up into 64% “red” cones, 32% “green” cones, and 2% “blue” cones. Most of these are packed into the fovea. Figure 2 shows how rods and cones are arranged in the retina. Rods are located mainly in the peripheral regions of the retina, and are absent from the middle of the fovea. Cones are located throughout the retina, but concentrated on the very centre.
Fig.2: Rods and cones in the retina.
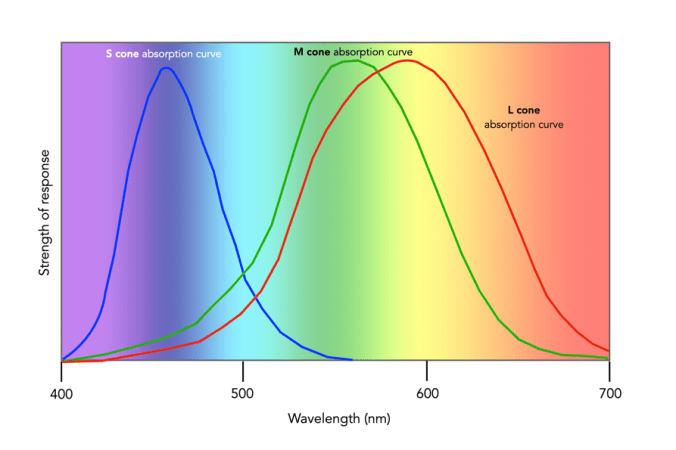
Since there are three types of cones, how are other colours formed? The ability to see millions of colours is a combination of the overlap of the cones, and how the brain interprets the information. Figure 3 shows roughly how the red, green, and blue sensitive cones interpret different wavelengths as colour. As different wavelengths stimulate the colour sensitive cones in differing proportions, the brain interprets the signals as differing colours. For example, the colour yellow results from the red and green cones being stimulated while the blues cones are not.
Fig.3: Response of the human visual system to light
Below is a list of approximately how the cones make the primary and secondary colours. All other colours are composed of varying strengths of light activating the red, green and blues cones. when the light is turned off, black is perceived.
The colour violet activates the blue cone, and partially activates the red cone.
The colour blue activates the blue cone.
The colour cyan activates the blue cone, and the green cone.
The colour green activates the green cone, and partially activates the red and blue cones.
The colour yellow activates the green cone and the red cone.
The colour orange activates the red cone, and partially activates the green cone.
The colour red activates the red cones.
The colour magenta activates the red cone and the blue cone.
The colour white activates the red, green and blue cones.
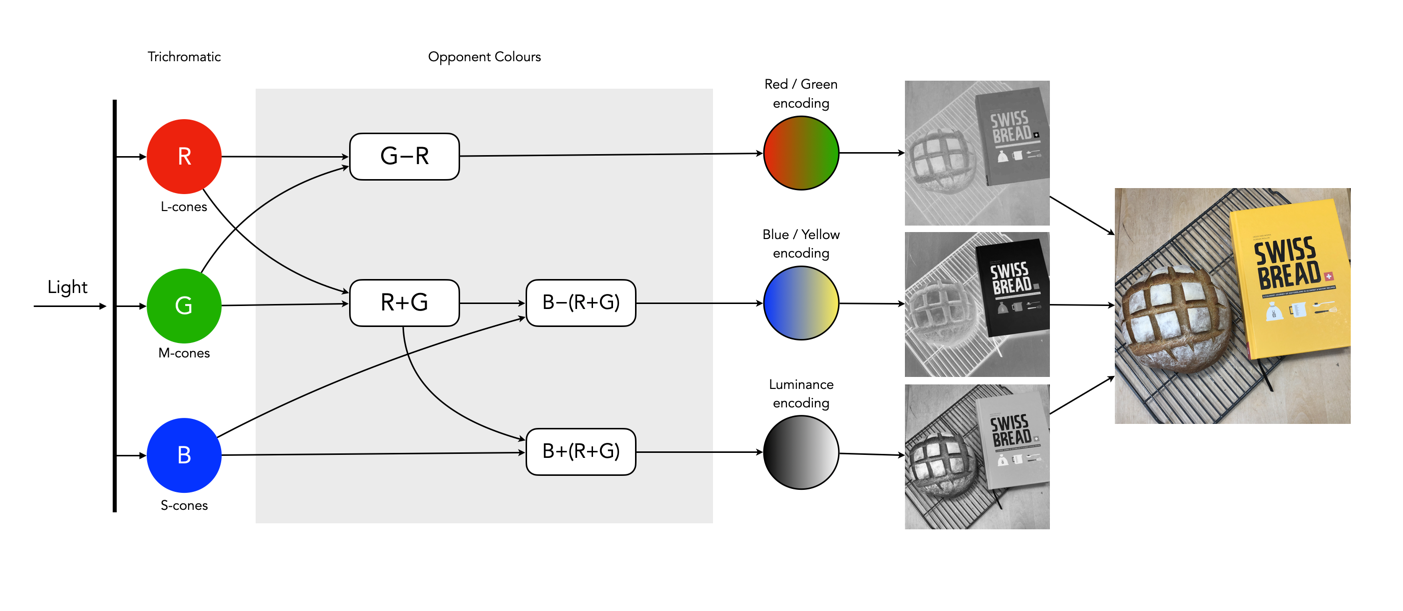
So what about post-processing once the cones have done their thing? The sensor array receives the colours, and stores the information by encoding it in the bipolar and ganglion cells in the retina before it is passed to the brain. There are three types of encoding.
The luminance (brightness) is encoded as the sum of the signals coming from the red, green and blue cones and the rods. These help provide the fine detail of the image in black and white. This is similar to a grayscale version of a colour image.
The second encoding separates blue from yellow.
The third encoding separates red and green.
Fig.4: The encoding of colour information after the cones do their thing.
In the fovea there are no rods, only cones, so the luminance ganglion cell only receives a signal from one cone cell of each colour. A rough approximation of the process is shown in Figure 4.
Now, you don’t really need to know that much about the inner workings of the eye, except that colour theory is based a great deal on how the human eye perceives colour, hence the use of RGB in digital cameras.