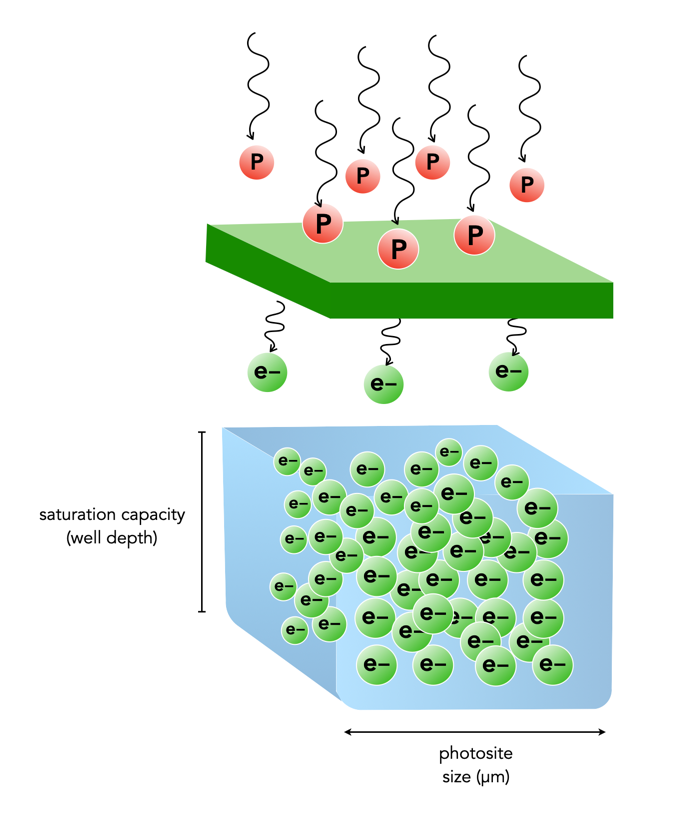
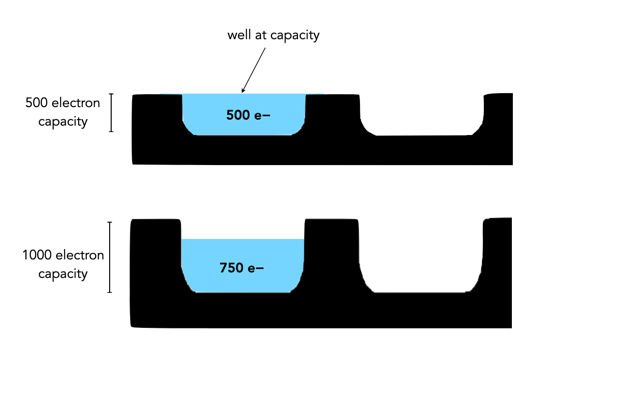
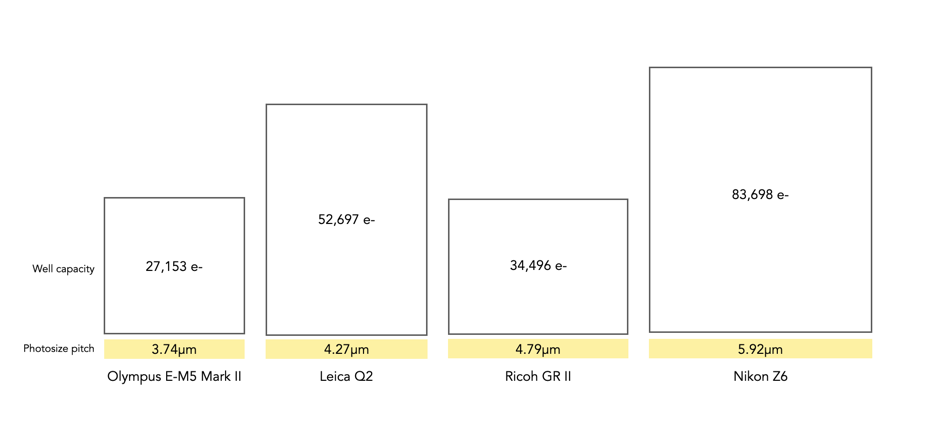
There is always a lot to think about when on the path to purchasing a new camera. In fact it may be one of the most challenging parts of getting started in photography, apart from choosing which lenses will be in your kit. It was frankly easier when there was less in the way of choices. You could make a list of 100 different things with which to compare cameras, but better to start with a simple series of things to consider.
Some people are likely swayed by fancy advertising, or cool features. Others think only of megapixels. There are of course many things to consider. This post aims to provide a simple insight into the sort of things you should consider when buying a digital camera. It is aimed at the pictorialist, or hobby/travel photographer. The first thing people think about when considering a camera is megapixels. These are important from a marketing perspective, mainly because they are a quantifiable number that can be sold to potential buyers. It is much harder to sell ISO or dynamic range. But megapixels aren’t everything, as I mentioned in a previous post, anywhere from 16-24 megapixels is fine. So if we move beyond the need for megapixels, what should we look for in a camera?
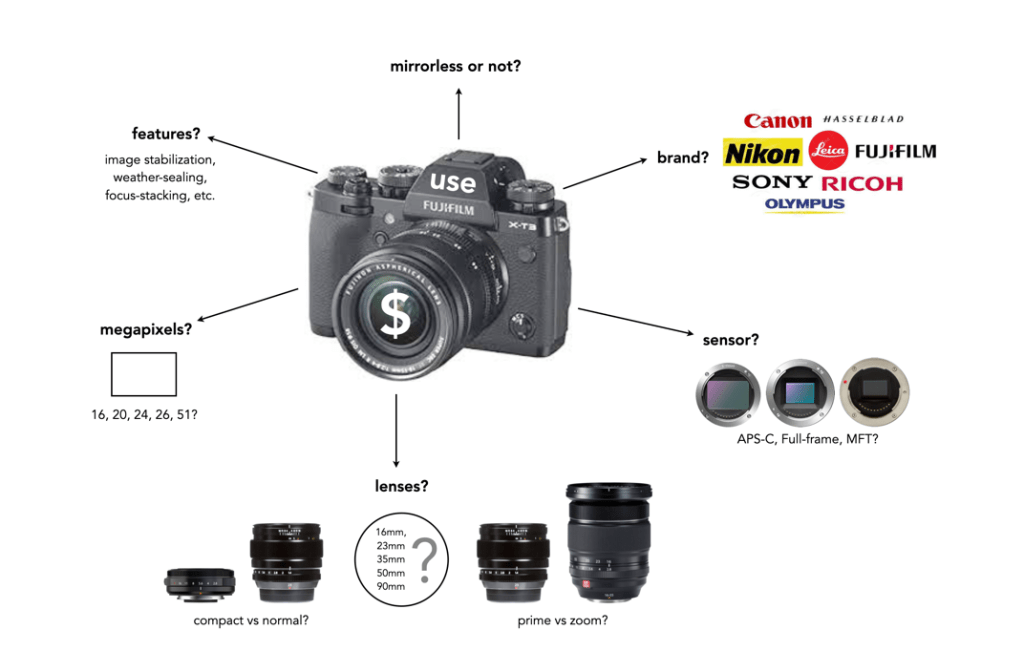
Perhaps the core requirement for a non-professional photographer is an understanding of what the camera is to be used for – landscapes, street photography, macro shooting, travel, blogging, video? This plays a large role in determining the type of camera from the perspective of the sensor. Full frame (FF) cameras are only required by the most dedicated of amateur photographers. For everyday shooting they can be far too bulky and heavy. At the other end of the spectrum is Micro-Four-Thirds (MFT), which is great for travelling because of it is compact size. In the middle are the cameras with APS-C sensors, sometimes often found in mirrorless cameras, and even compact fixed-lens format cameras. If you predominantly make videos, then a camera geared towards maybe less MP and more video features is essential. For street photography, perhaps something compact and unobtrusive. Many people also travel with a back-up camera, so there is that to consider as well.
Next is price, because obviously if I could afford it I would love a Leica… but in the real world it’s hard to justify. As the sensor gets larger, the price goes up accordingly. Large sensors cost more to make, and mechanisms such as image stabilization have to be scaled accordingly. Lenses for FF are also more expensive because they contain larger pieces of glass. It’s all relative – spend what you feel comfortable spending. It’s also about lifespan – how long will you use this camera? It was once about upgrading for more megapixels or fancy new features – it’s less about that now. Good cameras aren’t cheap – nothing in life is, neither are good lenses… but spend more for better quality and buy fewer lenses.
Then there are lenses. You don’t need dozens of them. Look at what lenses there are for what you want to do. You don’t need a macro lens if you are never going to take closeup shots, and fisheye lenses are in reality not very practical. Zoom lenses are the standard lenses supplied with many cameras, but the reality is a 24-80 is practical (although you honestly won’t use the telephoto function that much), anything beyond 80mm is likely not needed. Choose a good quality all round prime lens. There are also a variety of price points with lenses. Cheaper lenses will work fine but may not be as optically nice, have weather proofing or contain plastic instead of metal bodies. You can also go the vintage lens route – lots of inexpensive lenses to play with.
Now we get to the real Pandora’s Box – features. What extra features do you want? Are they features that you will use a lot? Focus stacking perhaps, for well focused macro shots. Manual focus helpers like focus peaking for use with manual lenses. High resolution mode? Image stabilization (IS)? I would definitely recommend IS but lean perhaps towards the in-body rather than the in-lens. In body means any lens will work with IS, even vintage ones. In lens is just too specialized and I favour less tech inside lenses. Features usually come at a price- battery drain, so think carefully about what makes sense for your particular situation.
So what to choose? Ultimately you can read dozens of reviews, watch reviews on YouTube, but you have to make the decision. If you’re unsure, try renting one for a weekend and try it out. There is no definitive guide to buying a digital camera, because there is so much to choose from, and everyone’s needs are so different.