How humans perceive colour is interesting, because the technology of how digital cameras capture light is adapted from the human visual system. When light enters our eye it is focused by the cornea and lens into the “sensor” portion of the eye – the retina. The retina is composed of a number of different layers. One of these layers contains two types of photosensitive cells (photoreceptors), rods and cones, which interpret the light, and convert it into a neural signal. The neural signals are collected and further processed by other layers in the retina before being sent to the brain via the optic nerve. It is in the brain that some form of colour association is made. For example, an lemon is perceived as yellow, and any deviation from this makes us question what we are looking at (like maybe a pink lemon?).
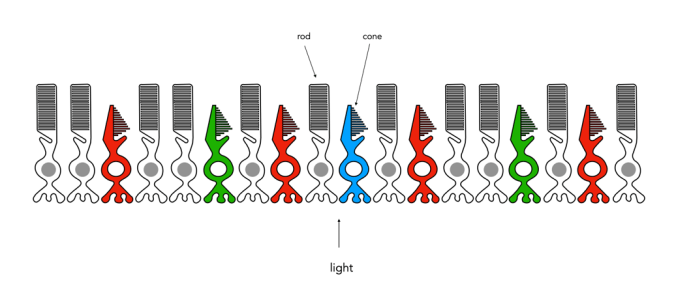
The rods, which are long and thin, interpret light (white) and darkness (black). Rods work only at night, as only a few photons of light are needed to activate a rod. Rods don’t help with colour perception, which is why at night we see everything in shades of gray. The human eye is suppose to have over 100 million rods.
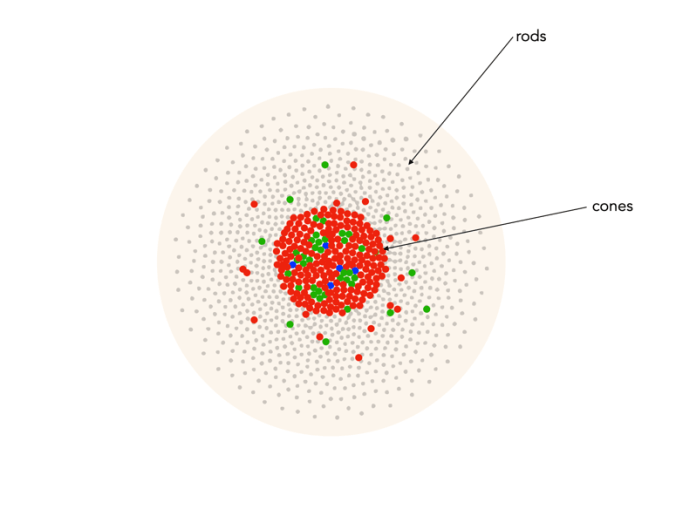
Cones have tapered shape, and are used to process the the three wavelengths which our brains interpret as colour. There are three types of cones – short-wavelength (S), medium-wavelength (M), and long-wavelength (L). Each cone absorbs light over a broad range of wavelengths: L ∼ 570nm, M ∼ 545nm, and S ∼ 440nm. The cones are usually called R, G, and B for L, M, and S respectively. Of course these cones have nothing to do with their colours, just wavelengths that our brain interprets as colours. There are roughly 6-7 million cones in the human eye, divided up into 64% “red” cones, 32% “green” cones, and 2% “blue” cones. Most of these are packed into the fovea. Figure 2 shows how rods and cones are arranged in the retina. Rods are located mainly in the peripheral regions of the retina, and are absent from the middle of the fovea. Cones are located throughout the retina, but concentrated on the very centre.
Since there are three types of cones, how are other colours formed? The ability to see millions of colours is a combination of the overlap of the cones, and how the brain interprets the information. Figure 3 shows roughly how the red, green, and blue sensitive cones interpret different wavelengths as colour. As different wavelengths stimulate the colour sensitive cones in differing proportions, the brain interprets the signals as differing colours. For example, the colour yellow results from the red and green cones being stimulated while the blues cones are not.
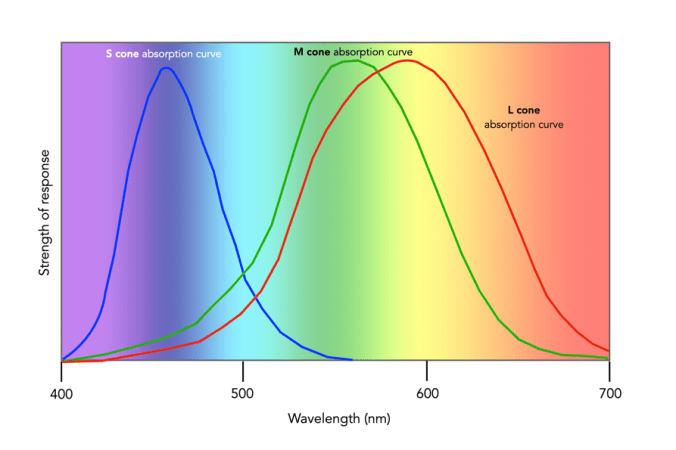
Below is a list of approximately how the cones make the primary and secondary colours. All other colours are composed of varying strengths of light activating the red, green and blues cones. when the light is turned off, black is perceived.
- The colour violet activates the blue cone, and partially activates the red cone.
- The colour blue activates the blue cone.
- The colour cyan activates the blue cone, and the green cone.
- The colour green activates the green cone, and partially activates the red and blue cones.
- The colour yellow activates the green cone and the red cone.
- The colour orange activates the red cone, and partially activates the green cone.
- The colour red activates the red cones.
- The colour magenta activates the red cone and the blue cone.
- The colour white activates the red, green and blue cones.
So what about post-processing once the cones have done their thing? The sensor array receives the colours, and stores the information by encoding it in the bipolar and ganglion cells in the retina before it is passed to the brain. There are three types of encoding.
- The luminance (brightness) is encoded as the sum of the signals coming from the red, green and blue cones and the rods. These help provide the fine detail of the image in black and white. This is similar to a grayscale version of a colour image.
- The second encoding separates blue from yellow.
- The third encoding separates red and green.
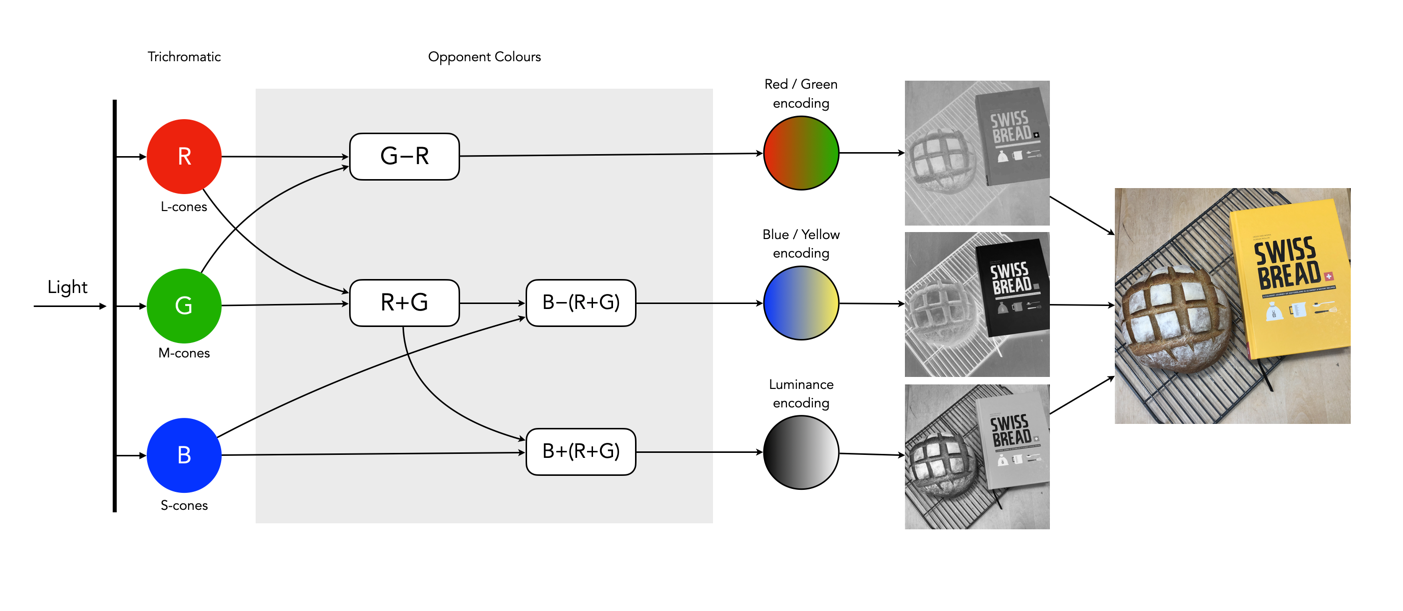
In the fovea there are no rods, only cones, so the luminance ganglion cell only receives a signal from one cone cell of each colour. A rough approximation of the process is shown in Figure 4.
Now, you don’t really need to know that much about the inner workings of the eye, except that colour theory is based a great deal on how the human eye perceives colour, hence the use of RGB in digital cameras.






