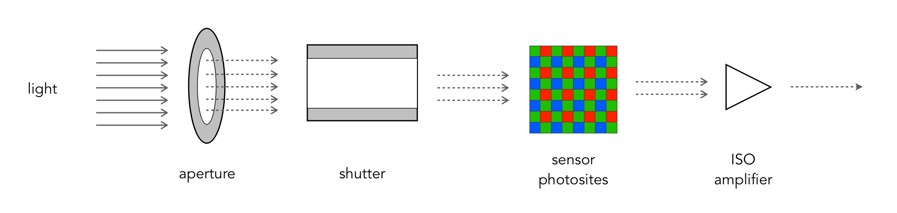
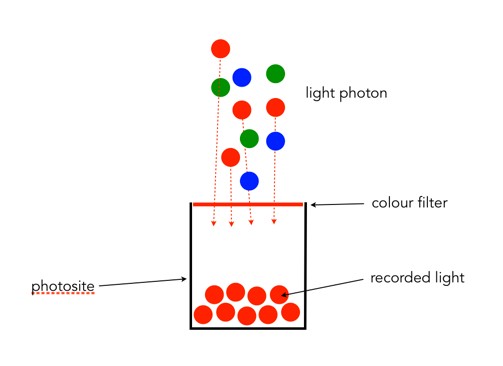
Photographs, and the results obtained through image processing are at the mercy of the human visual system. A machine cannot interpret how visually appealing an image is, because aesthetic perception is different for everyone. Image sharpening takes advantage of one of the tricks of our visual system. Human eyes see what are termed “Mach bands” at the edges of sharp transitions, which affect how we perceive images. This optical illusion was first explained by Austrian physicist and philosopher Ernst Mach (1838–1916) in 1865. Mach discovered how our eyes leverage the use of contrast to compensate for its inability to resolve fine detail. Consider the image below containing ten squares of differing levels of gray.

Notice how the gray squares appear to scallop, with a lighter band on the left, and a darker band on the right of the squares? This is an optical illusion, in fact the gray squares are all uniform in intensity. To resolve the brain/eyes deficiency in being able to resolve detail, incoming light gets processed in such a manner than the contrast between two different tones is exaggerated. This gives the perception of more detail. The dark and light bands seen on either side of the gradation are the Mach bands. Here is an example of what human eyes see:
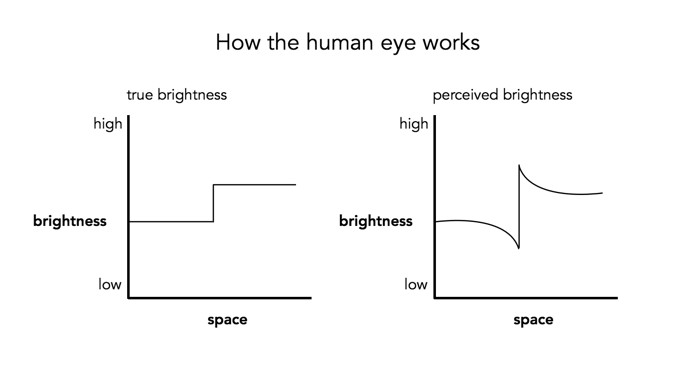
What does this have to do with manipulation techniques such as image sharpening? The human brain perceives exaggerated intensity changes near edges – so image sharpening uses this notion to introduce faux Mach bands by amplifying intensity edges. Consider as an example the following image, which basically shows two mountain sides, one behind the other. Without looking too closely you can see the Mach bands.

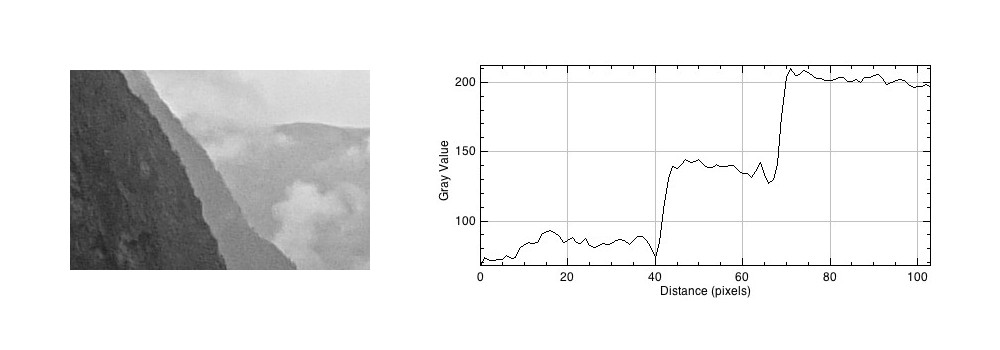
Taking a profile perpendicular to the mountain sides provides an indication of the intensity values along the profile, and shows the edges.
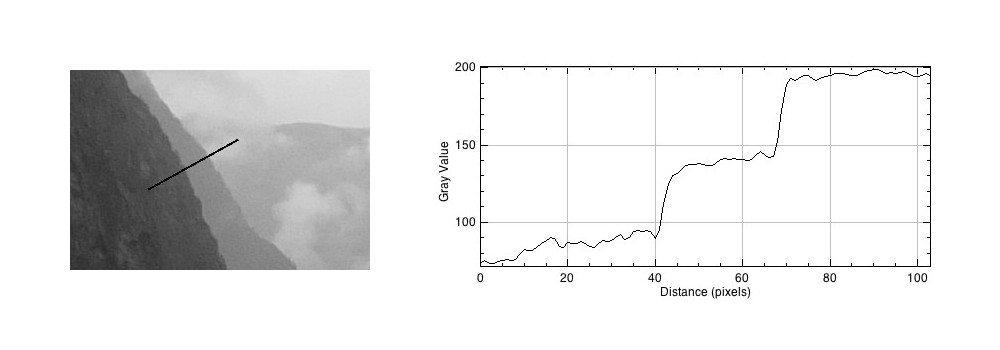
The profile shows three plateaus, and two cliffs (the cliffs are ignored by the human eyes). The first plateau is the foreground mountainside, the middle plateau is the mountainside behind that, and the uppermost plateau is some cloud cover. Now we apply an unsharp masking filter to the image, to sharpen the image (radius=10, mask weight=0.4)
Notice how the UM filter has the effect of adding a Mach band to each of the cliff regions.