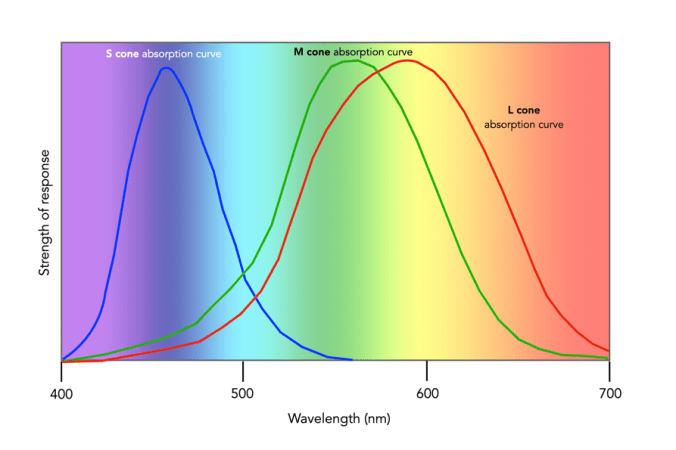
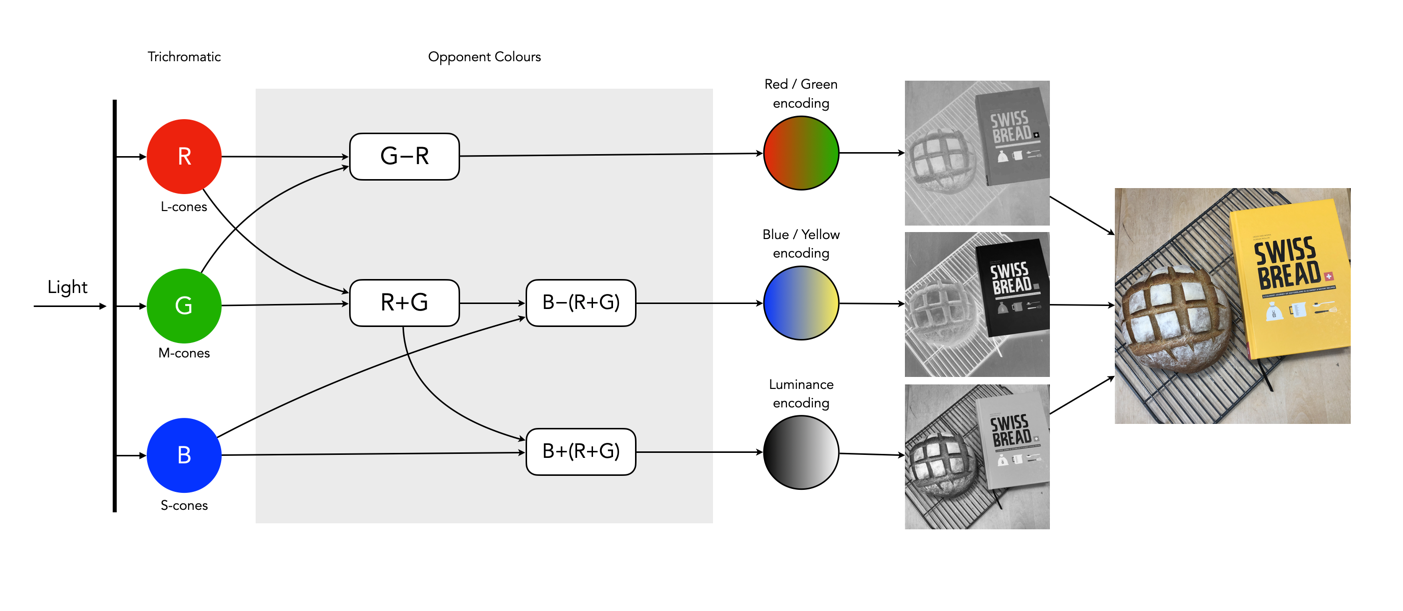
A standard colour image is 8-bit (or 24-bit) containing 2563 = 16,777,216 colours. That seems like a lot right? But can that many colours even be distinguished by the human visual system? The quick answer is no, or rather we don’t exactly know for certain. Research into the number of actual discernible colours is actually a bit of a rabbit’s hole.
A 1998 paper [1] suggests that the number of discernible colours may be around 2.28 million – the authors determined this by calculating the number of colours within the boundary of the MacAdam Limits in CIELAB Uniform Colour Space [2] (for those who are interested). However even the authors suggested this 2.28M may be somewhat of an overestimation. An larger figure of 10 million colours (from 1975) is often cited [3], but there is no information on the origin of this figure. A similar figure of 2.5 million colours was cited in a 2012 article [4]. A more recent article [5] gives a conservative estimate of 40 million distinguishable object color stimuli. Is it even possible to realistically prove such large numbers? Somewhat unlikely, because it may be impossible to quantify – ever. Indications based on existing colour spaces may be as good as it gets, and frankly even 1-2 million colours is a lot.
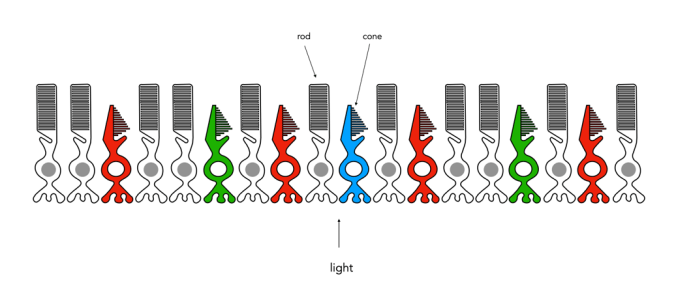
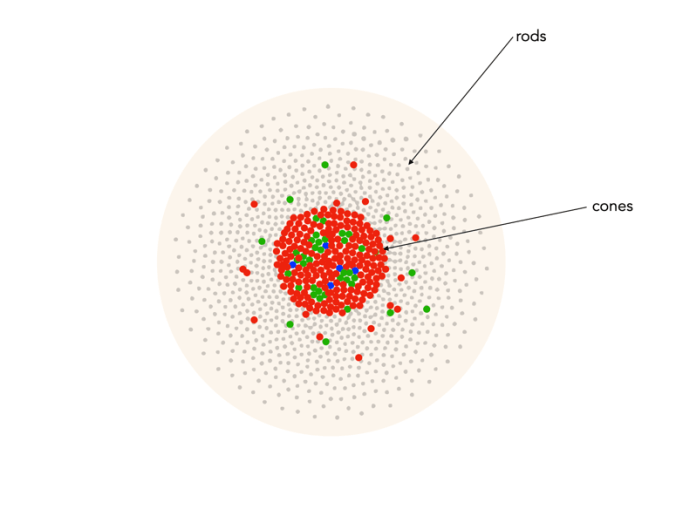
Of course the actual number of colours someone sees is also dependent on the number and distribution of cones in the eye. For example, dichromat’s only have two types of cones which are able to perceive colour. This colour deficiency manifests differently depending on which cone is missing. The majority of the population are trichromats, i.e. they have three types of cones. Lastly there are the very rare individuals, the tetrachromats who have four different cones. Supposedly tetrachromats can see 100 million colours, but it is thought the condition only exists in women, and in reality, nobody really knows how many are potentially tetrachromatic [6] (and the only definitive way of finding out if you have tetrachromacy is via a genetic test).
The reality is that few if any real pictures contain 16 million colours. Here are some examples (all images contain 9 million pixels). Note the images are shown in association with the hue distribution from the HSB colour-space. The first example is a picture of a wall of graffiti art in Toronto. Now this is an atypical image because it contains a lot of varied colours, most images do not. This image has only 740,314 distinct colours – that’s only 4.4% of the potential colours available.

The next example is a more natural picture, a picture of two building (Nova Scotia). This picture is quite representative of images such as landscapes, that are skewed towards quite a narrow band of colours. It only contains 217,751 distinct colours, or 1.3% of the 16.77 million colours.

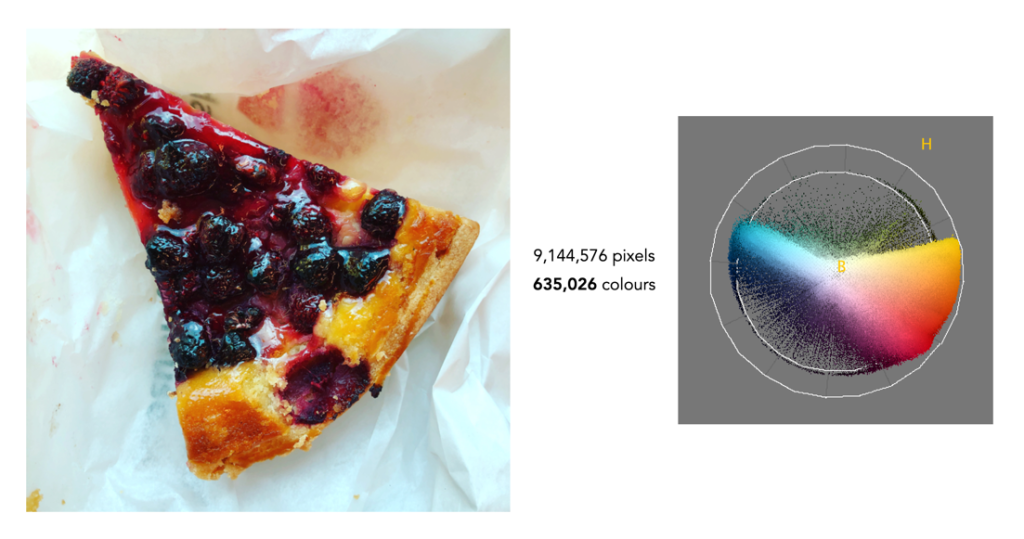
Finally we have foody-type image that doesn’t seem to have a lot of differing colours, but in reality it does. There are 635,026 (3.8%) colours in the image. What these examples show is that most images contain fewer than one million different colours. So while there is the potential for an image to contain 16,777,216 colours, in all likely they won’t.
What about 10-bit colour? We’re taking about 10243 or 1,073,741,824 colours – which is really kind of ridiculous.
Further reading:
- Pointer, M.R., Attridge, G.G., “The number of discernible colours”, Color Research and Application, 23(1), pp.52-54 (1998)
- MacAdam, D.L., “Maximum visual efficiency of colored materials”, Journal of the Optical Society of America, 25, pp.361-367 (1935)
- Judd, D.B., Wyszecki, G., Color in Business, Science and Industry, Wiley, p.388 (1975)
- Flinkman, M., Laamanen, H., Vahimaa, P., Hauta-Kasari, M., “Number of colors generated by smooth nonfluorescent reflectance spectra”, J Opt Soc Am A Opt Image Sci Vis., 29(12), pp.2566-2575 (2012)
- Kuehni, R.G., “How Many Object Colors Can We Distinguish?”, Color Research and Application, 41(5), pp.439-444 (2016)
- Jordan, G., Mollon, J., “Tetrachromacy: the mysterious case of extra-ordinary color vision”, Current Opinion in Behavioral Sciences, 30, pp.130-134 (2019)
- All the Colors We Cannot See, Carl Jennings (June 24, 2019)
- How Many Colors Can Most Of Us Actually See, USA Art News (July 23, 2020)