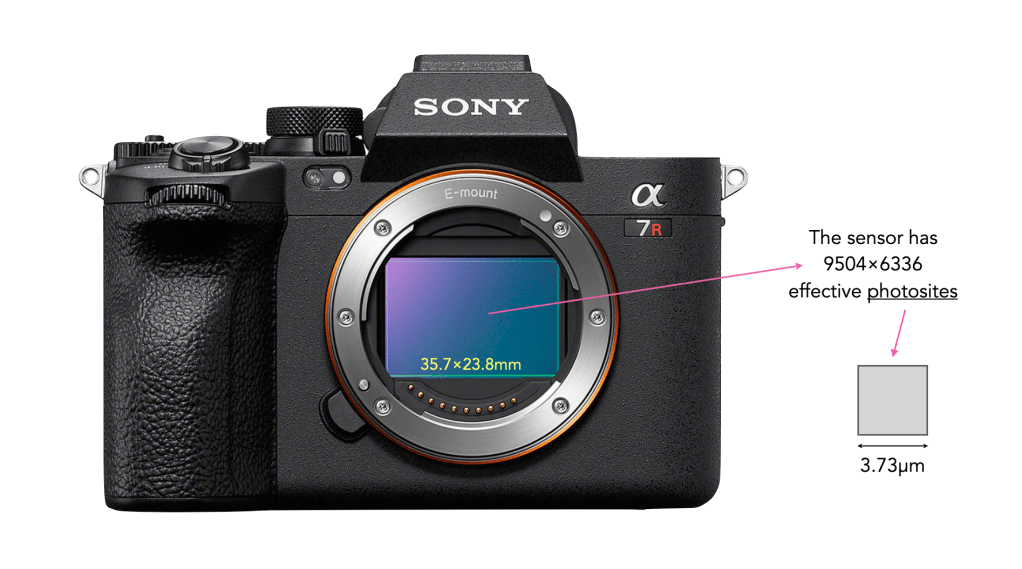
The funny thing about the photosites on a sensor is that they are mostly designed to pick up one colour, due to the specific colour filter associated with with photosite. Therefore a normal sensor does not have photosites which contain full RGB information.
To create an image from a photosite matrix it is first necessary to perform a task called demosaicing (or demosaiking, or debayering). Demosaicing separates the red, green, and blue elements of the Bayer image into three distinct R, G, and B components. Note a colouring filtering mechanism other than Bayer may be used. The problem is that each of these layers is sparse – the green layer contains 50% green pixels, and the remainder are empty. The red and blue layers only contain 25% of red and blue pixels respectively. Values for the empty pixels are then determined using some form of interpolation algorithm. The result is an RGB image containing three layers representing red, green and blue components for each pixel in the image.
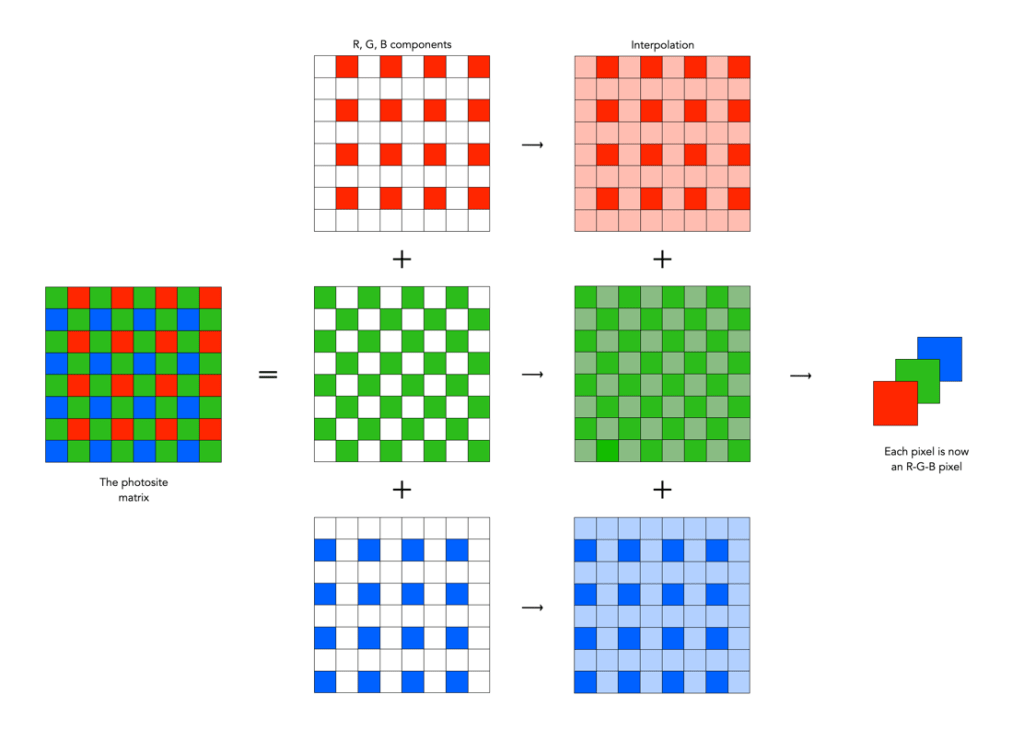
There are a myriad of differing interpolation algorithms, some which may be specific to certain manufacturers (and potentially proprietary). Some are quite simple, such as bilinear interpolation, while others like bicubic interpolation, spline interpolation, and Lanczos resampling are more complex. These methods produce reasonable results in homogeneous regions of an image, but can be susceptible to artifacts near edges. This leads to more sophisticated algorithms such as Adaptive Homogeneity-Directed, and Aliasing Minimization and Zipper Elimination (AMaZE).
An example of bilinear interpolation is shown in the figure below (note that no cameras actually use bilinear interpolation for demosaicing, but it offers a simple example to show what happens). For example extracting the red component from the photosite matrix leaves a lot of pixels with no red information. These empty reds are interpolated from existing red information in the following manner: where there was previously a green pixel, red is interpolated as the average of the two neighbouring red pixels; and where there was previously a blue pixel, red is interpolated as the average of the four (diagonal) neighbouring red pixels. This way the “empty” pixels in the red layer are interpolated. In the green layer every empty pixel is simply the average of the neighbouring four green pixels. The blue layer is similar to the red layer.

❂ The only camera sensors that don’t use this principle are the Foveon-type sensors which have three separate layers of photodetectors (R,G,B). So stacked the sensor creates a full-colour pixel when processed, without the need for demosaicing. Sigma has been working on a full-frame Foveon sensor for years, but there are a number of issues still to be dealt with including colour accuracy.