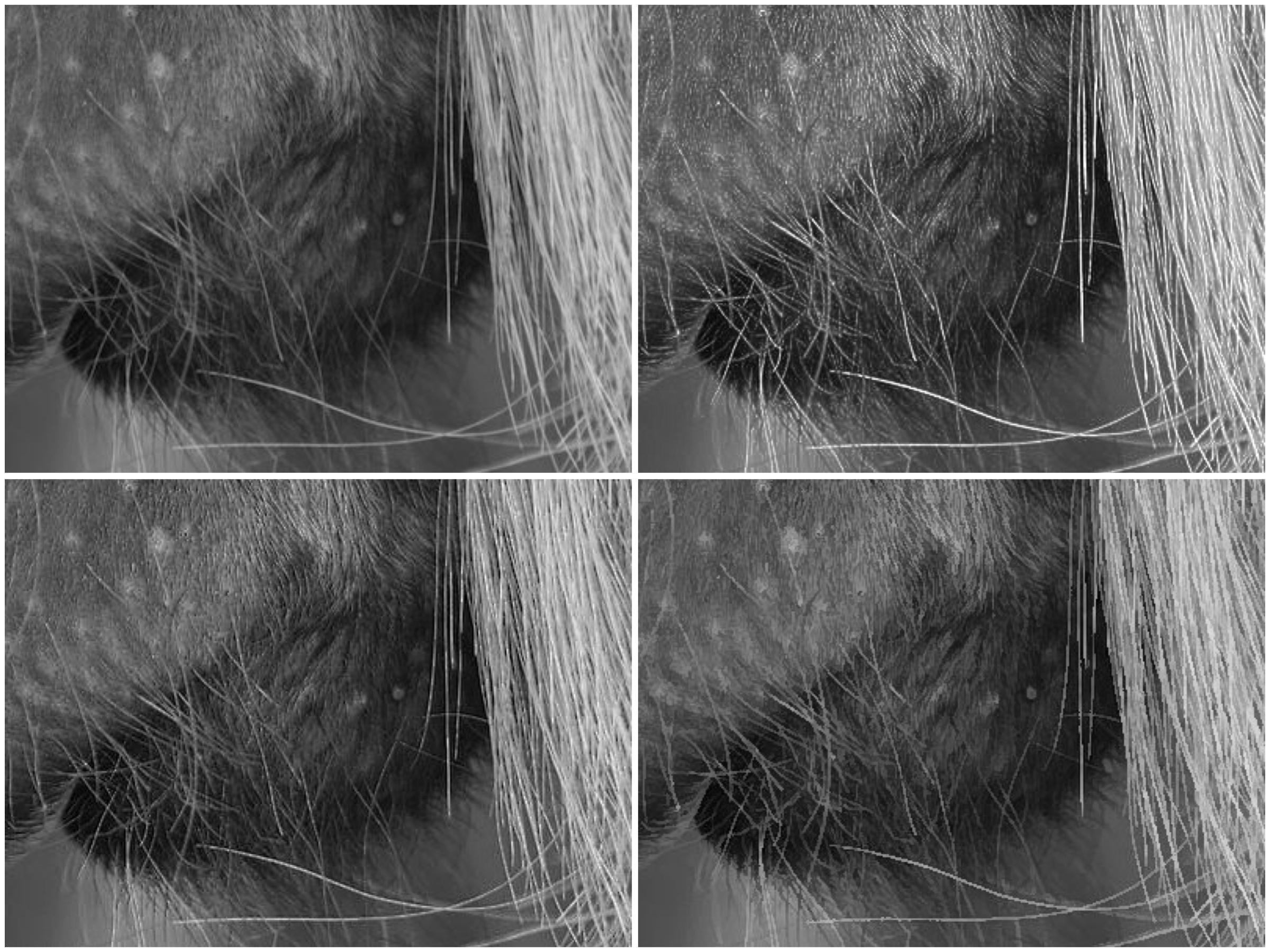
Pixels actually help define image resolution. Image resolution is the level of visual detail in an image, and is usually represented as the number of pixels in an image. An image with a high density of pixels will have a higher resolution, providing both better definition, and more details. An image with low resolution will have less pixels and consequently less details and definition. Resolution is the difference between a 24MP image, and a 4MP image. Consider the example below which shows four different resolutions of the same image, shown as they would appear on a screen.

Each image is ¼ the size of the previous image, meaning it has 75% less detail. However it is hard to determine how much detail has been lost. In some cases the human visual system will compensate for details lost by filling in information. To understand how resolution impacts the quality of an image, it is best to look the images using the same image dimensions. This means zooming in the images with less resolution so they appear the same size as the 100% image.

You can clearly see that when the resolution of an image decreases, the finer details tend to get washed out. This is especially prevalent in regions of this image which have text. Low resolution essentially means details become pixelated or blobby. These examples are quite extreme of course. With the size of modern camera sensors, taking a 24MP (6000×4000) image, and reducing it 25% would still result in an image 1500×1000 pixels in size. The quality of these lower resolution images is actually perceived to be quite good, because of the limited resolution of screens. Below is an example of a high resolution image and the same image in low resolution at 1/8th the size.

They are perceptually quite similar. It is not until one enlarges a region that the degradation becomes clear. These artifacts are particularly prevalent in fine details, such as text.