People take photographs for a number of reasons. People process images for a number of reasons. Some people (like me) spend as little time as possible post-processing images, others spend hours in applications like Photoshop, tweaking every possible part of an image. To each their own. There are others still who like to tinker with the techniques themselves, writing their own software to process their images. There are many different things to consider, and my hope in this post is to try and look at what it means to create your own image processing programs to manipulate images.

1. What do you want to achieve?
The first thing to ask is what do you want to achieve? Do you want to implement algorithms you can’t find in regular photo manipulating programs? Do you want to batch process images? There are various different approaches here. If you want to batch process images, for example converting hundreds of images to another file format, or automatically generating histograms of images, then it is possible to learn some basic scripting, and use existing image manipulation programs such as ImageMagick. If you want to write heavier algorithms, for example some fancy new Instagram-like filter, then you will have to learn how to program using a programming language.
2. To program you need to understand algorithms
Programming of course is not a trivial thing, as much as people like to make it sound easy. It is all about taking an algorithm, which is a precise description of a method for solving a problem, and translating it into a program using a programming language. The algorithms can already exist, or they can be created from scratch. For example, a Clarendon-like (Instagram) image filter can be reproduced with the following algorithm (shown visually below):
- Read in an image from file.
- Add a blue tint to the image by blending it with a blue image of the same size (e.g. R=127, G=187, B=227, opacity = 20%).
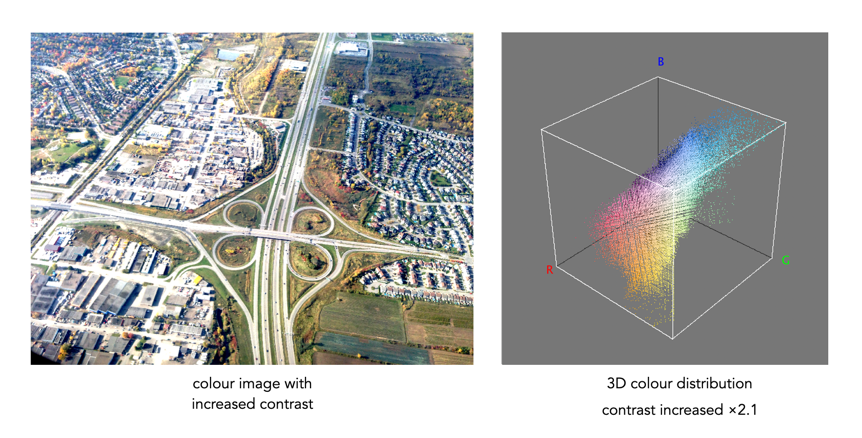
- Increase the contrast of the image by 20%.
- Increase the saturation of the image by 35%.
- Save the new Clarendon-like filtered image in a new file.

To reproduce any of these tasks, we need to have an understanding of how to translate the algorithm into a program using a programming language, which is not always a trivial task. For example to perform the task of increasing the saturation of an image, we have to perform a number of steps:
- Convert the image to a colour model which allows saturation to be easily modified, for example HSI, which has three component layers: Hue, Saturation, and Intensity.
- Increase in saturation by manipulating the Saturation layer, i.e. multiplying all values by 1.2.
- Convert the image from HSI back to RGB.
Each of these tasks in turn requires additional steps. You can see this could become somewhat long-winded if the algorithm is complex.
3. To implement algorithms you need a programming language
The next trick is the programming language. Most people don’t really want to get bogged down in programming because of the idiosyncrasies of programming languages. But in order to convert an algorithm to a program, you have to choose a programming language, and learn how to code in it.
There are many programming languages, some are old, some are new. Some are easier to use than others. Novice programmers often opt for a language such as Python which is easy to learn, and offers a wide array of existing libraries or algorithms. The trick with programming is that you don’t necessarily want to reinvent the wheel. You don’t want to have to implement an algorithm that already exists. That’s why programming languages provide functions like sqrt() and log(), so people don’t have to implement them. For example, Akiomi Kamakura has already created a Python library called Pilgram, which contains a series of mimicked Instragram filters (26 of them), some CSS filters, and blend modes. So choosing Python means that you don’t have to build these from scratch, if anything they might provide inspiration to build your own filters. For example the following Python program uses Pilgram to apply the Clarendon filter to a JPG image:
from PIL import Image
import pilgram
import os
inputfile = input('Enter image filename (jpg): ')
base = os.path.splitext(inputfile)[0]
outputfile = base + '-clarendon.jpg'
print(base)
print(outputfile)
im = Image.open(inputfile)
pilgram.clarendon(im).save(outputfile)
The top part of the program imports the libraries, the middle portion deals with obtaining the filename of the image to be processed, and producing an output filename, and the last two lines actually open the image, process it with the filter, and save the filtered image. Fun right? But you still have to learn how to code in Python. Python comes with it’s own baggage (like dependencies, and being uber slow), but overall it is still a solid language, and easy to learn for novices. There are also other computer vision/image processing libraries such as scikit-image, SimpleCV and OpenCV. And in reality that is the crux here, programming for beginners.
If you really want to program in a more “complex” language, like C or C++ there is often a much steeper learning curve, and fewer libraries. I would not advocate for a fledgling programmer to learn any C-based language, only because it will result in being bogged down by the language itself. For the individual hell-bent on learning one of these languages I would suggest Fortran. Fortran was the first high-level programming language, introduced in 1957, however it has evolved, and modern Fortran is easy to learn, and use. It doesn’t come with much in the way of image processing libraries, but if you persevere you can build them.